Redis
一.基础使用
Redis简介
Redis是一个基于内存的 key-value 结构数据库。
基于内存存储,读写性能高
适合存储热点数据(热点商品、资讯、新闻)
企业应用广泛
官网:https://redis.io
中文网:
https://www.redis.net.cn/
Redis启动
Windows:
1 | redis-server.exe redis.windows.conf |
Linux:
1 | redis-server |
根据配置文件启动
1 | redis-server redis.conf |
配置
Windows:在redis.windows.conf
1 | redis.windows.conf |
Linux:/usr/local/src/redis-x.x/erdis-conf
Redis存储的是key-value结构的数据,其中key是字符串类型,value有5种常用的数据类型
字符串(string):普通字符串,Redis中最简单的数据类型
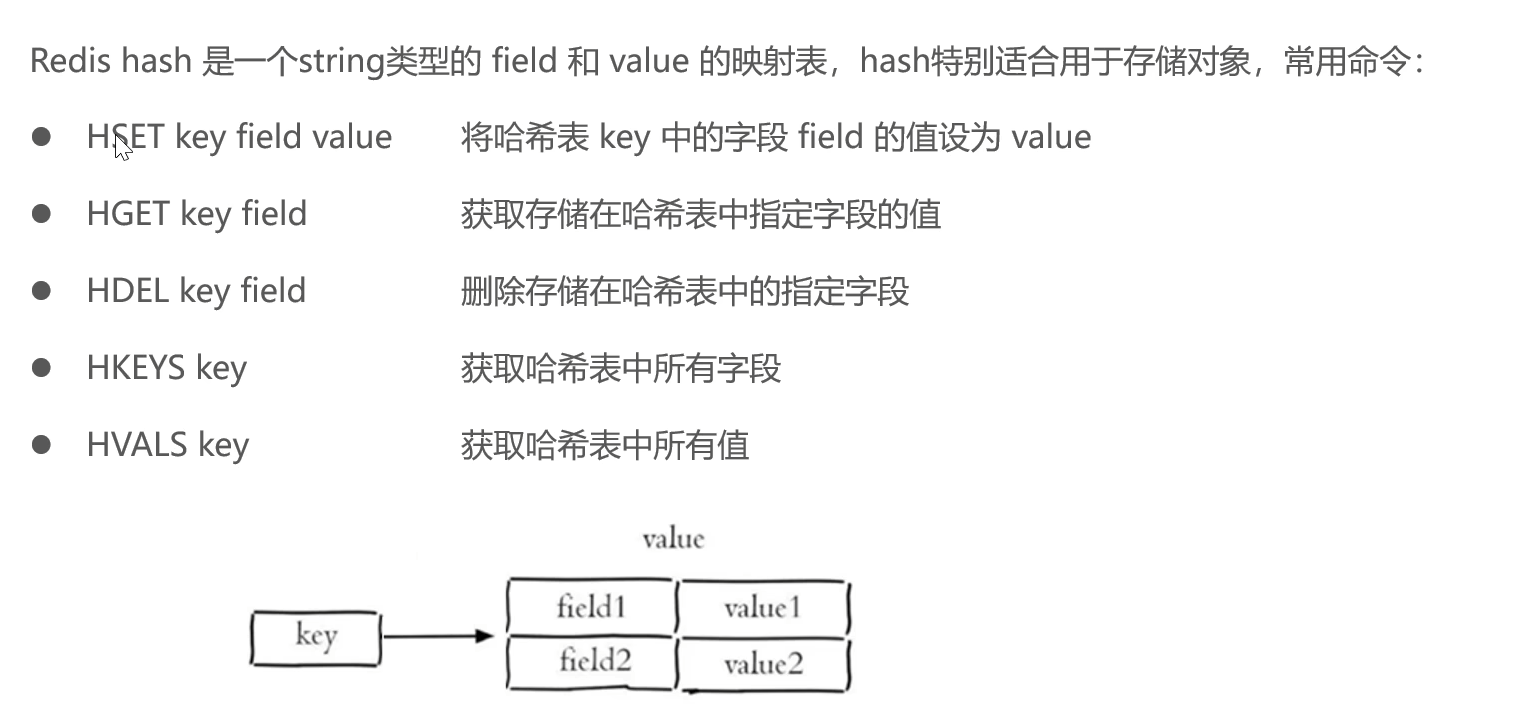
哈希(hash):也叫散列,类似于Java中的HashMap结构
列表(list):按照插入顺序排序,可以有重复元素,类似于Java中的LinkedList
集合(set):无序集合,没有重复元素,类似于Java中的Hashset
有序集合(sorted set/zset):集合中每个元素关联一个分数
(score),根据分数升序排序,没有重复元素
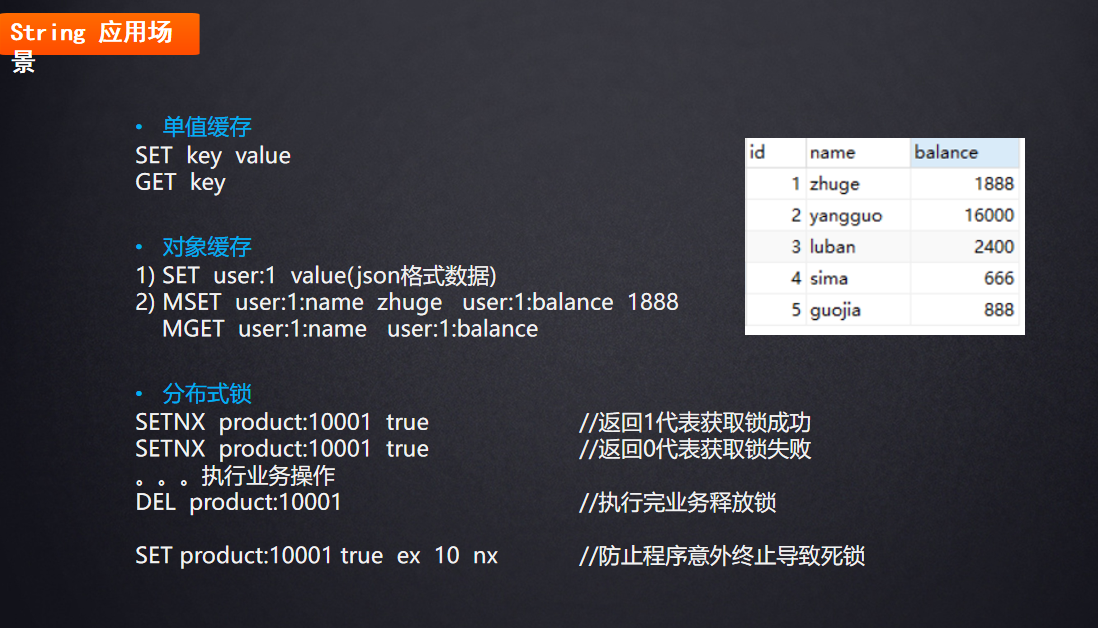
字符串操作命令

1 | // 测试字符串的存取 |
应用场景

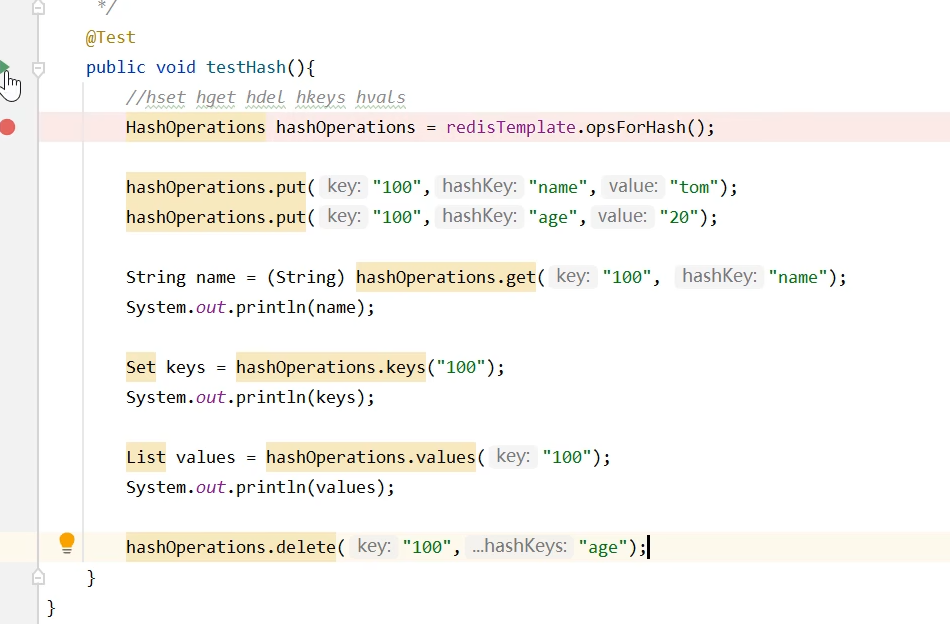
哈希操作命令
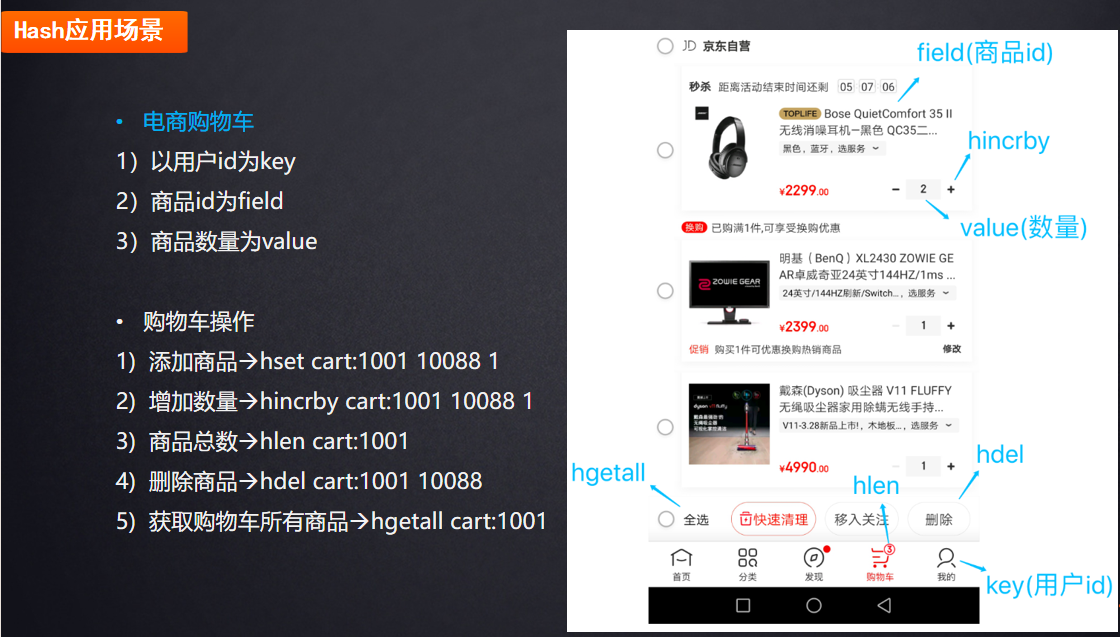
应用场景

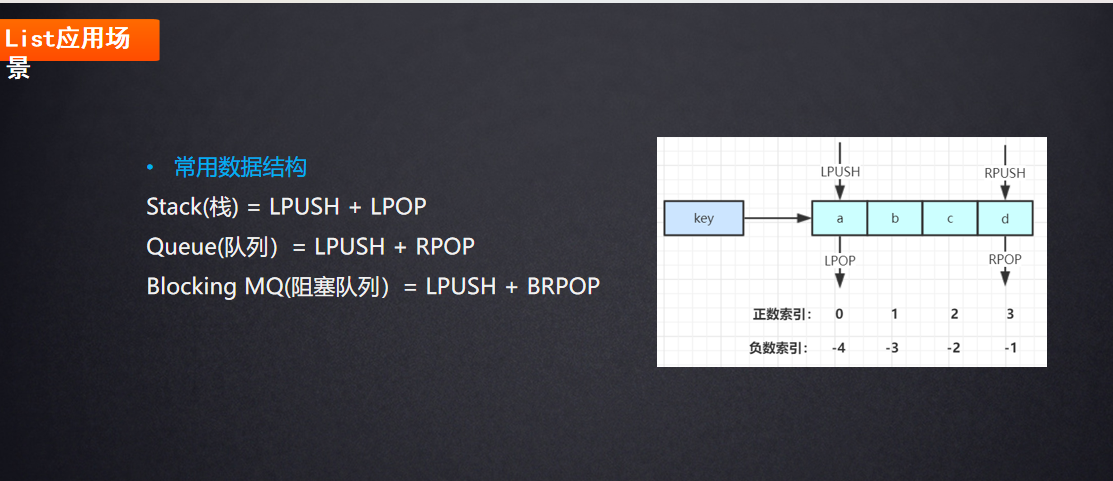
列表操作命令

应用场景
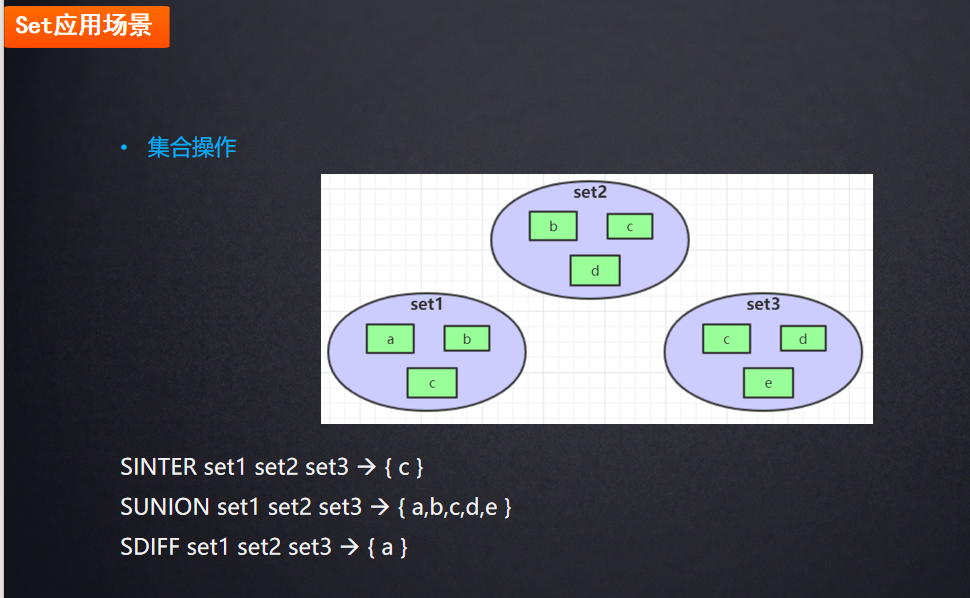
集合操作命令

SDIFF 是集合(Set)数据类型的命令,用于计算多个集合的差集(即属于第一个集合但不属于其他集合的元素),并返回结果
应用场景



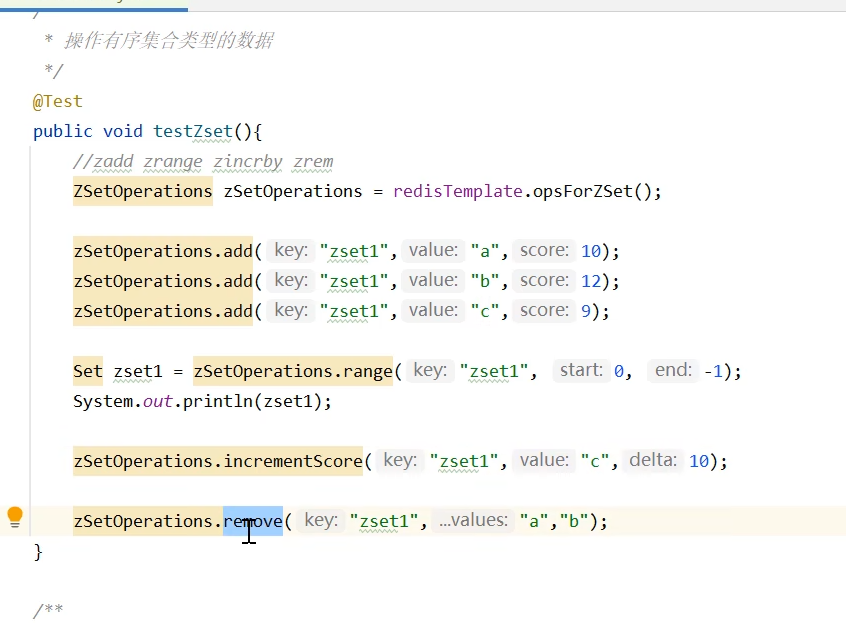
有序集合操作命令

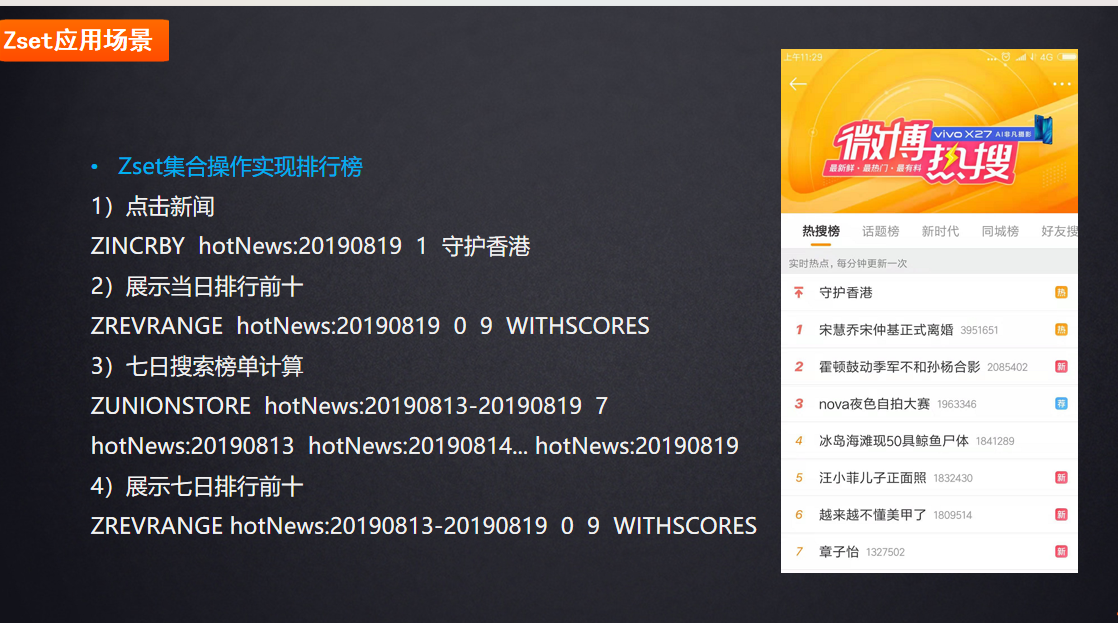
应用场景
通用命令
 scan:渐进式遍历键
scan:渐进式遍历键
1 | SCAN cursor [MATCH pattern] [COUNT count] |
scan 参数提供了三个参数,第一个是 cursor 整数值(hash桶的索引值),第二个是 key 的正则模式,
第三个是一次遍历的key的数量(参考值,底层遍历的数量不一定),并不是符合条件的结果数量。第
一次遍历时,cursor 值为 0,然后将返回结果中第一个整数值作为下一次遍历的 cursor。一直遍历
到返回的 cursor 值为 0 时结束。
注意:但是scan并非完美无瑕, 如果在scan的过程中如果有键的变化(增加、 删除、 修改) ,那
么遍历效果可能会碰到如下问题: 新增的键可能没有遍历到, 遍历出了重复的键等情况, 也就是说
scan并不能保证完整的遍历出来所有的键, 这些是我们在开发时需要考虑的。

GEO 数据结构
GEO 就是 Geolocation 的简写形式,代表地理坐标。Redis 在 3.2 版本中加入了对 GEO 的支持,允许存储地理坐标信息,帮助我们根据经纬度来检索数据。常见的命令有:
- GEOADD:添加一个地理空间信息,包含:经度(longitude)、纬度(latitude)、值(member)
- GEODIST:计算指定的两个点之间的距离并返回
- GEOHASH:将指定 member 的坐标转为 hash 字符串形式并返回
- GEOPOS:返回指定 member 的坐标
- GEORADIUS:指定圆心、半径,找到该圆内包含的所有 member,并按照与圆心之间的距离排序后返回。6.2 以后已废弃
- GEOSEARCH:在指定范围内搜索 member,并按照与指定点之间的距离排序后返回。范围可以是圆形或矩形。6.2 新功能
- GEOSEARCHSTORE:与 GEOSEARCH 功能一致,不过可以把结果存储到一个指定的 key。6.2 新功能
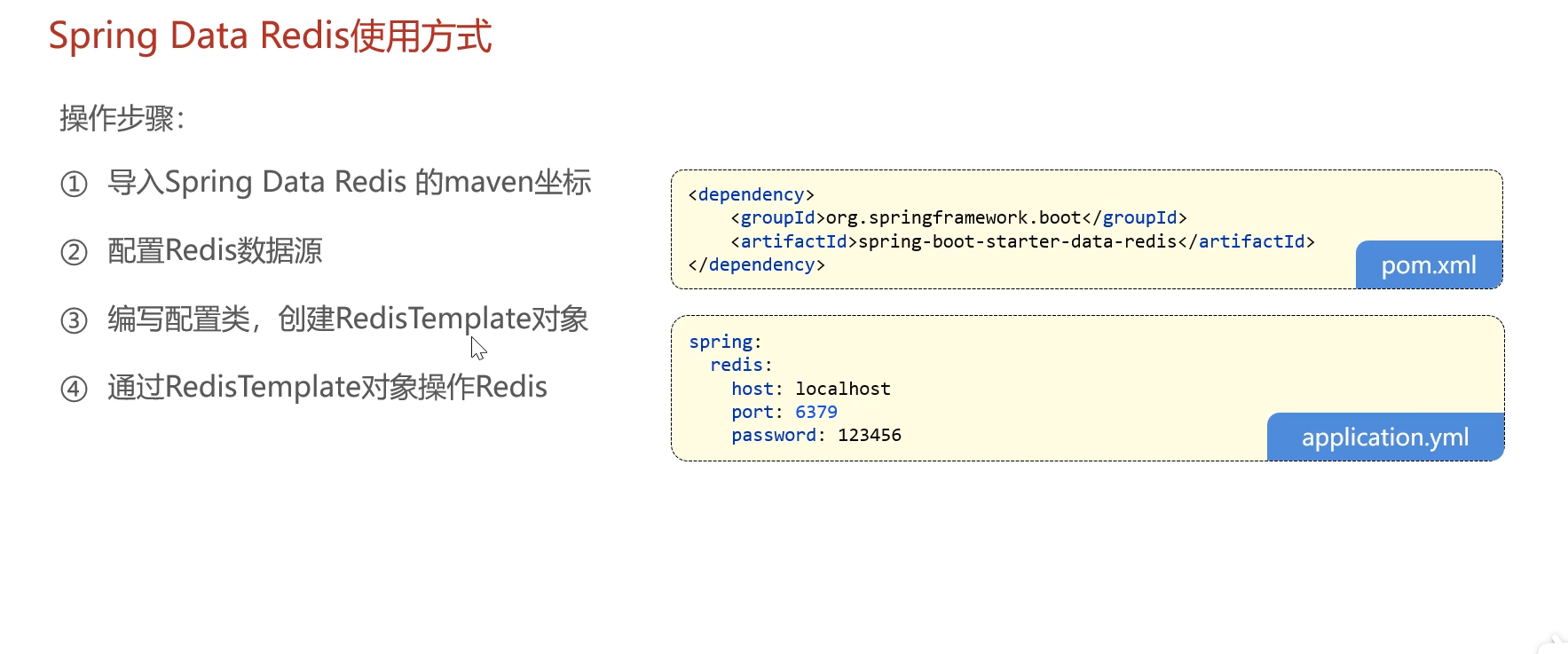
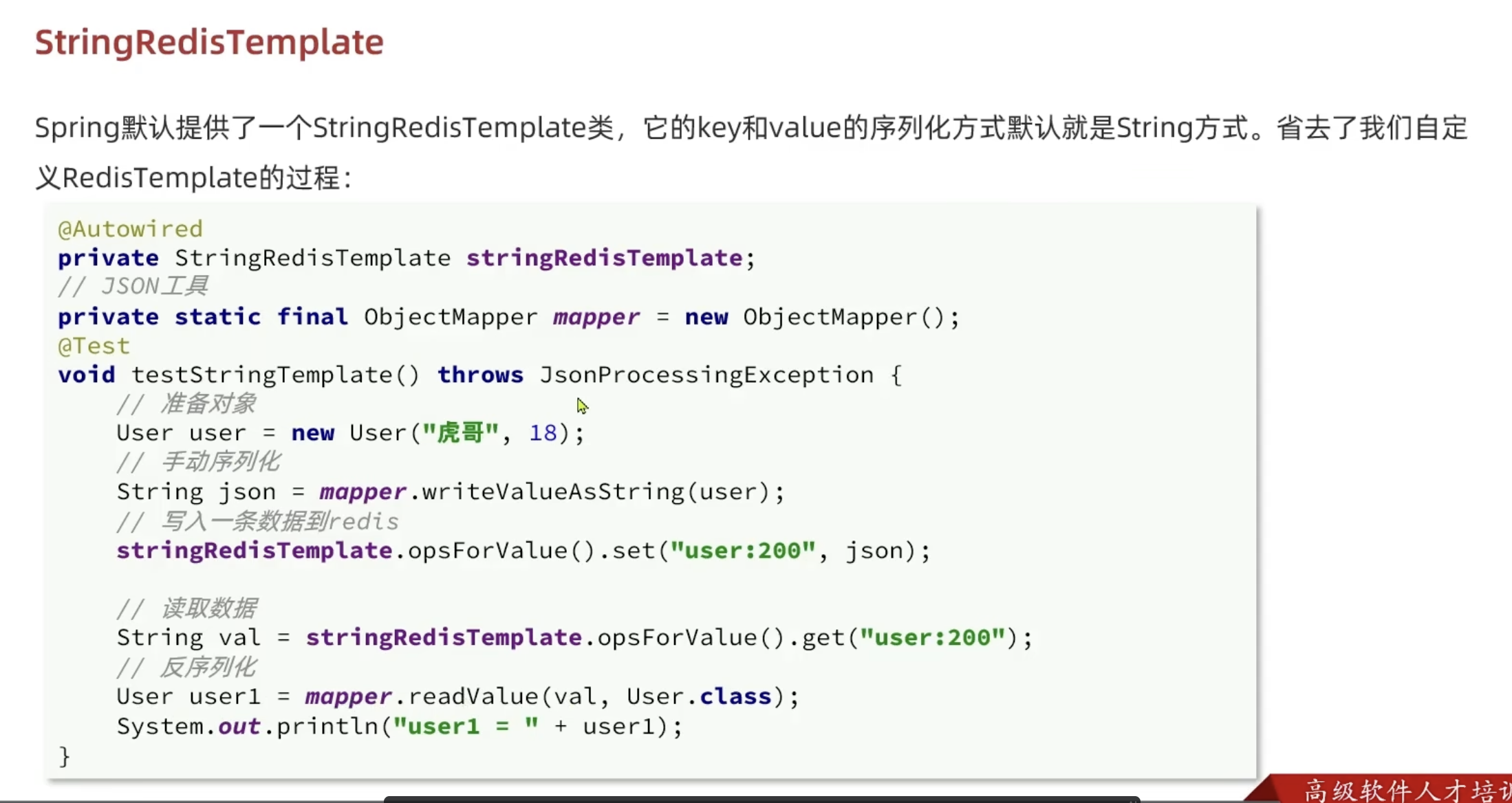
在Spring项目使用Redis


序列化问题
乱码,内存占用大



为了节省内存空间,存储 Java 对象还是需要手动序列化和反序列化,注入StringRedisTemplate对象就可以。
二.Redis的单线程和高性能
Redis是单线程吗?
Redis 的单线程主要是指 Redis 的网络 IO 和键值对读写是由一个线程来完成的,这也是 Redis 对外提供键值存储服务的主要流程。但 Redis 的其他功能,比如持久化、异步删除、集群数据同步等,其实是由额外的线程执行的。
Redis 单线程为什么还能这么快?
因为它所有的数据都在内存中,所有的运算都是内存级别的运算,而且单线程避免了多线程的切换性能损耗问题。正因为 Redis 是单线程,所以要小心使用 Redis 指令,对于那些耗时的指令(比如keys),一定要谨慎使用,一不小心就可能会导致 Redis 卡顿。
Redis 单线程如何处理那么多的并发客户端连接?
Redis的IO多路复用:redis利用epoll来实现IO多路复用,将连接信息和事件放到队列中,依次放到
文件事件分派器,事件分派器将事件分发给事件处理器。
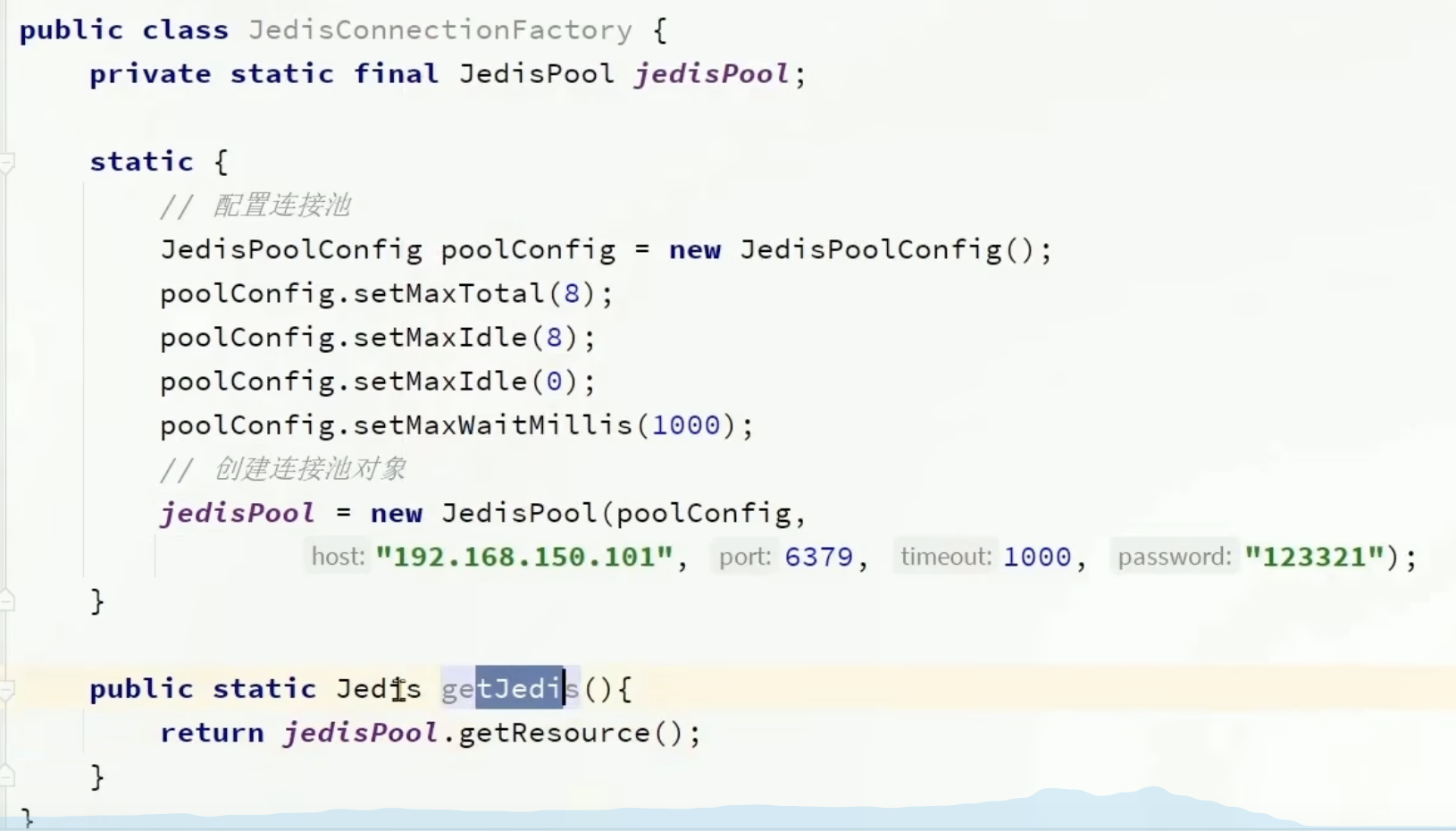
Jedis 配置连接池
缓存相关
缓存更新策略分为:内存淘汰(内存不足自动淘汰旧数据)、超市剔除、主动更新。
高一致性需求采用主动更新。
redis 缓存主动更新策略
1.Cache Aside Pattern(缓存旁路模式),是最常用的缓存与数据库协同策略之一,核心逻辑是由缓存的调用者(业务系统)自己负责同步缓存和数据库—— 更新数据时,先操作数据库,再同步更新缓存(或者删除缓存)。
2.Read/Write Through(读写穿透)模式是一种缓存与数据库的协同策略,核心特点是将缓存和数据库整合为一个服务,由这个服务统一处理数据的读写,同时负责维护缓存与数据库的一致性。
3.Write Behind Caching(写回缓存)模式,是一种缓存与数据库的异步协同策略,核心逻辑是:
- 调用者只操作缓存:业务系统写数据时,只更新缓存,不直接操作数据库;
- 异步持久化:由专门的线程(或后台进程)异步地把缓存中的数据同步到数据库;
- 一致性保证:这种模式不保证 “实时一致”,而是保证最终一致性(缓存和数据库的数据最终会同步)。
它的优势是写操作性能高(调用者不用等待数据库写入完成),但缺点是如果缓存故障(比如宕机),未同步到数据库的数据可能丢失。
一般采用第一种,从线程安全考虑要先操作数据库,再删缓存
缓存穿透
缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。这意味着在高并发的情况下,数据库会搞垮。
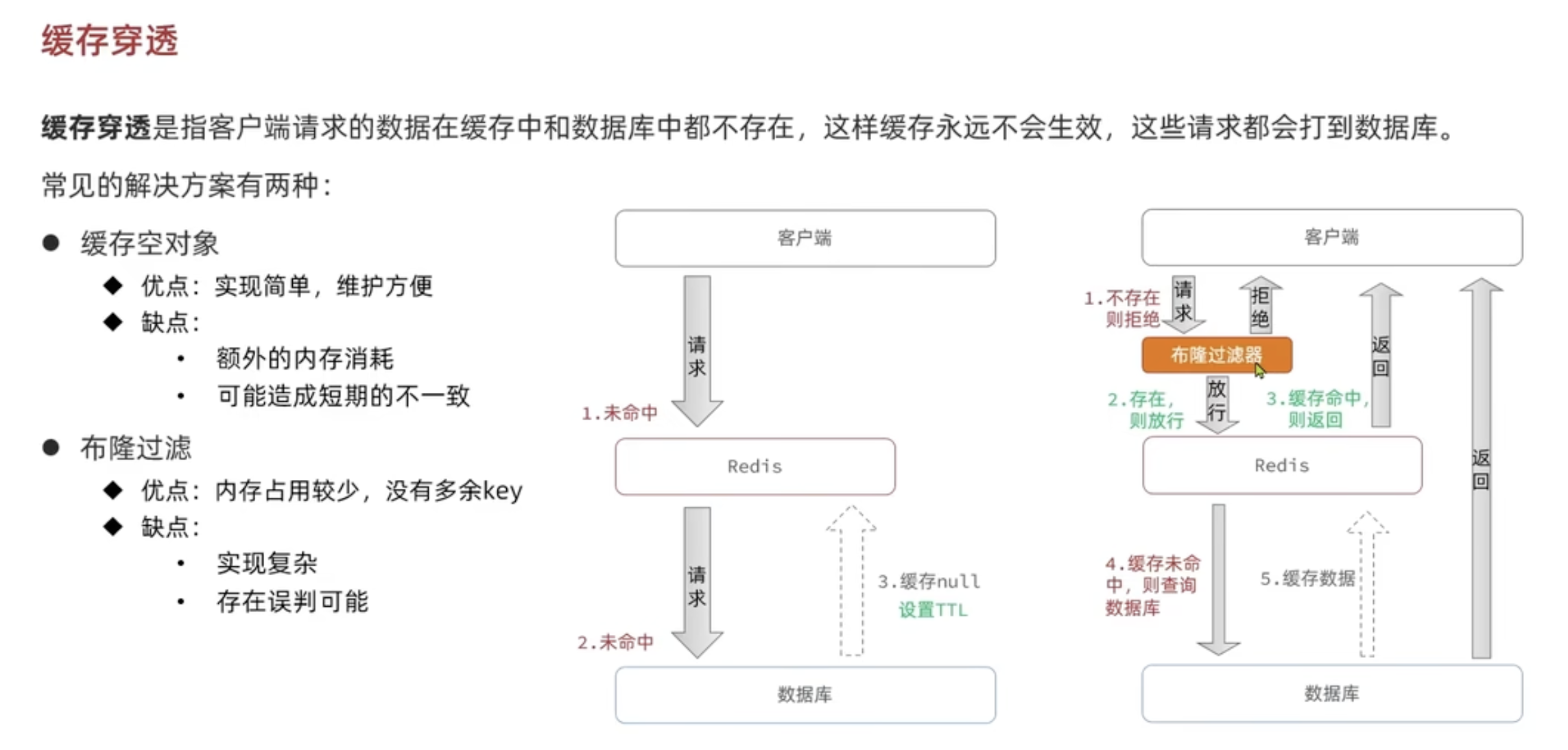
常见解决方案:
缓存空对象
- 流程:请求缓存 / 数据库都没数据时,在缓存中存一个 “空值”(并设过期时间 TTL),后续同请求直接读缓存的空值。
- 优点:实现简单、维护方便。
- 缺点:占额外内存;空值过期前可能和数据库数据不一致(比如数据库后来新增了该数据)。
布隆过滤器
- 流程:先通过布隆过滤器判断数据 “是否存在”—— 不存在则直接拒绝请求;存在则放行,再查缓存 / 数据库。
- 优点:内存占用较少,没有多余 key
- 缺点:实现复杂;存在误判可能(不存在的数据判断成存在从而在数据库查)
- (注:布隆过滤器是一种空间高效的概率型数据结构,能快速判断 “数据不存在”,但有极低的误判率)
其他:
- 增强id的复杂度,避免被猜测id规律
- 做好数据的基础格式校验
- 加强用户权限校验
- 做好热点参数的限流
缓存雪崩
缓存雪崩是指在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
解决方案:
• 给不同的Key的TTL添加随机值
• 利用Redis集群提高服务的可用性
• 给缓存业务添加降级限流策略
• 给业务添加多级缓存
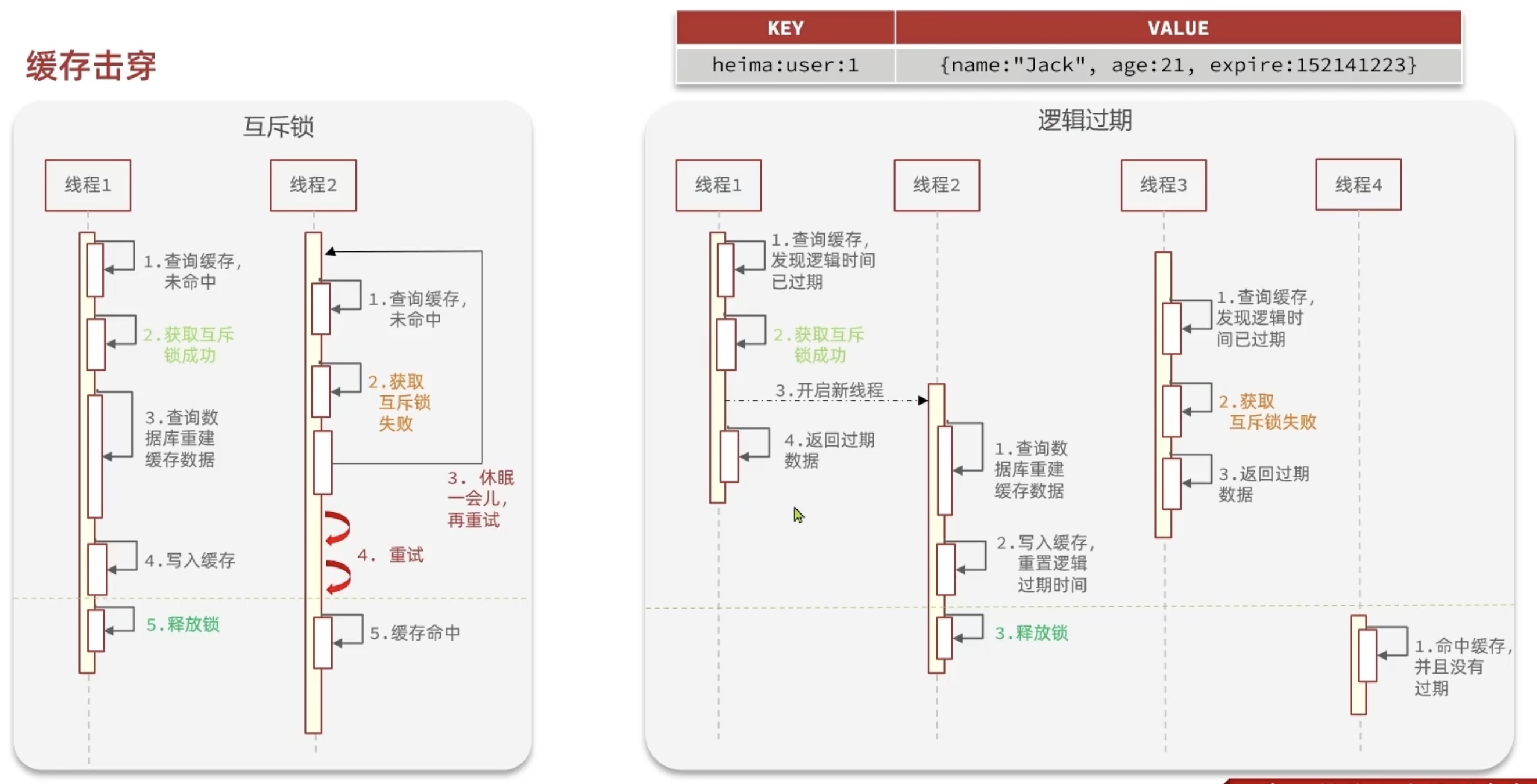
缓存击穿
缓存击穿问题也叫热点Key问题,就是一个被高并发访问并且缓存重建业务较复杂的key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击。
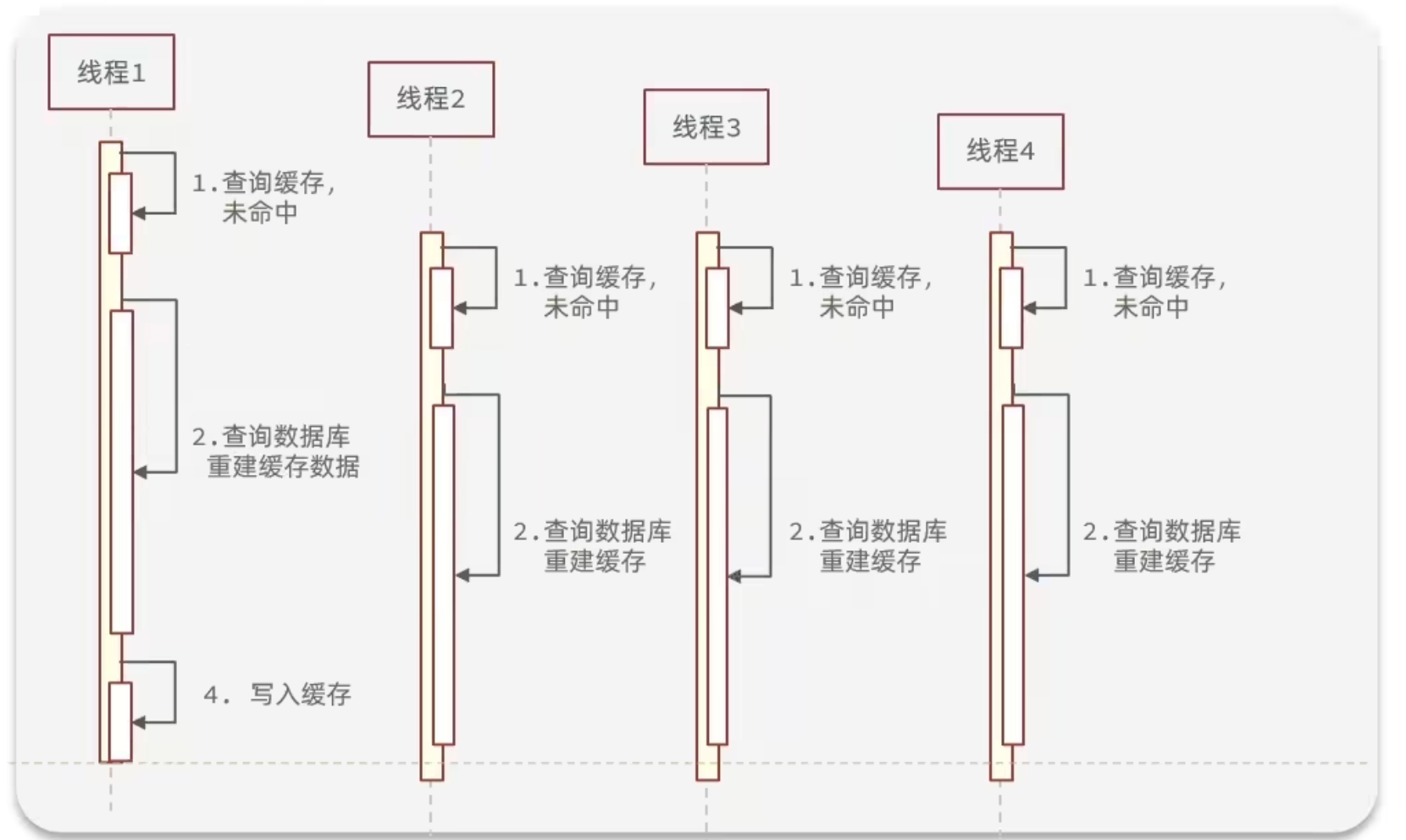
解决方案:
- 互斥锁
- 逻辑过期
解决方案对比
| 解决方案 | 优点 | 缺点 |
|---|---|---|
| 互斥锁 | - 无额外内存消耗 - 保证数据一致性 - 实现简单 |
- 线程需等待,性能受影响 - 存在死锁风险 |
| 逻辑过期 | - 线程无需等待,性能较好 | - 不保证数据一致性 - 有额外内存消耗 - 实现复杂 |
互斥锁直接 setnx 就行(setnx 表示没有值才能 set 成功)

全局唯一 ID
在分布式系统需要使用全局唯一 ID 生成工具
要满足:唯一性、高可用、高性能、递增性、安全性
基于时间戳和 Redis 的原子性自增操作实现全局唯一 ID:

ID的组成部分:
•符号位:1bit,永远为0
•时间戳:31bit,以秒为单位,可以使用69年
•序列号:32bit,秒内的计数器,支持每秒产生2^32个不同ID
代码示例:
 测试:
测试:

其他生成策略 UUID、雪花算法
多线程并发问题
超卖问题

悲观锁:认为线程安全问题一定会发生,在操作数据前先获取锁,使得线程串行执行。比如 Synchronized、Lock
乐观锁:认为线程安全问题不一定会发生,只是在更新数据时判断有没有其他线程修改了数据,有就重试或抛异常,没有就更新。
乐观锁
版本号法: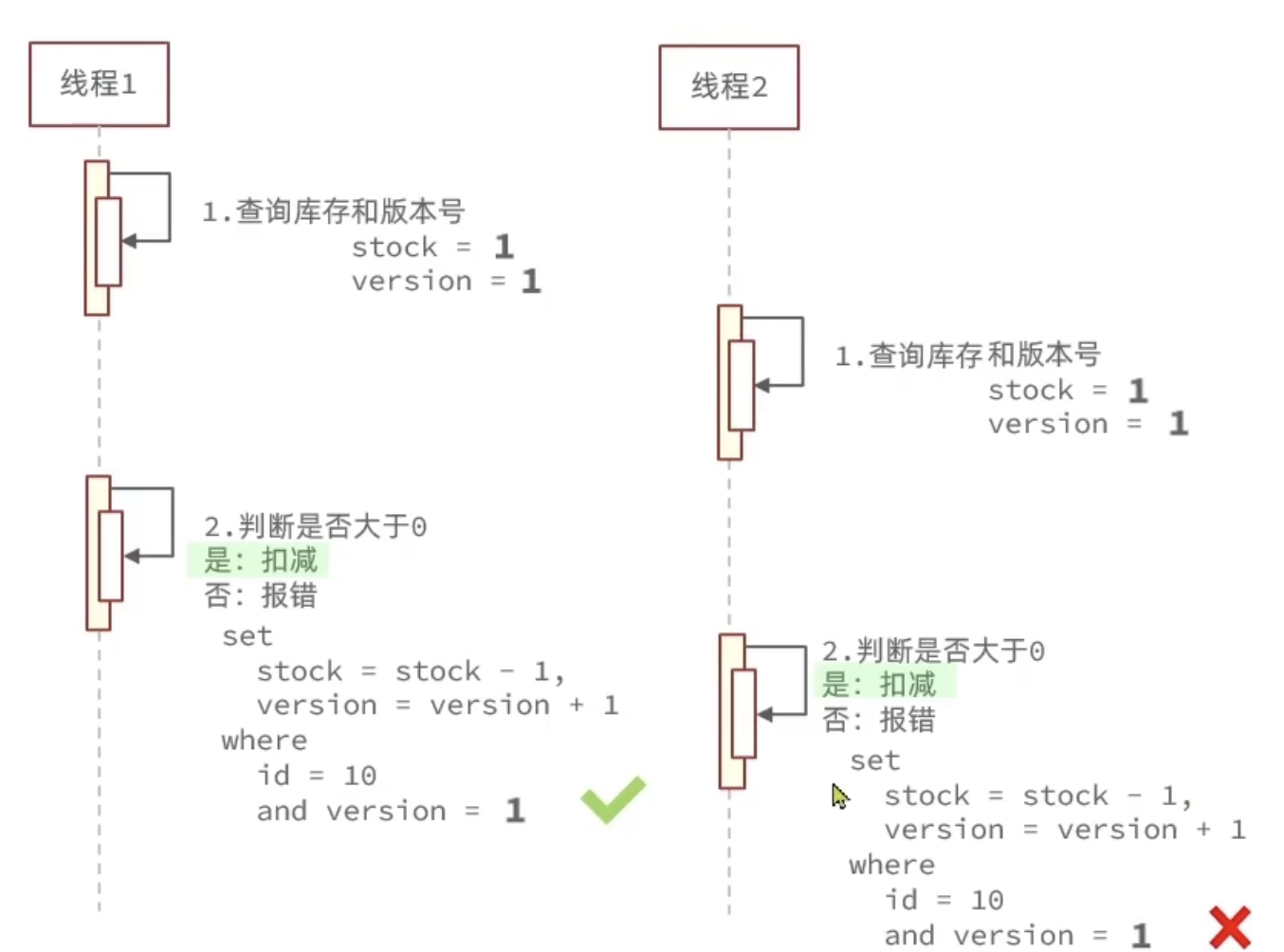
在修改前查版本号,在更新数据时比对版本号是否变动并更新版本号。
CAS 法:(Compare And Swap)
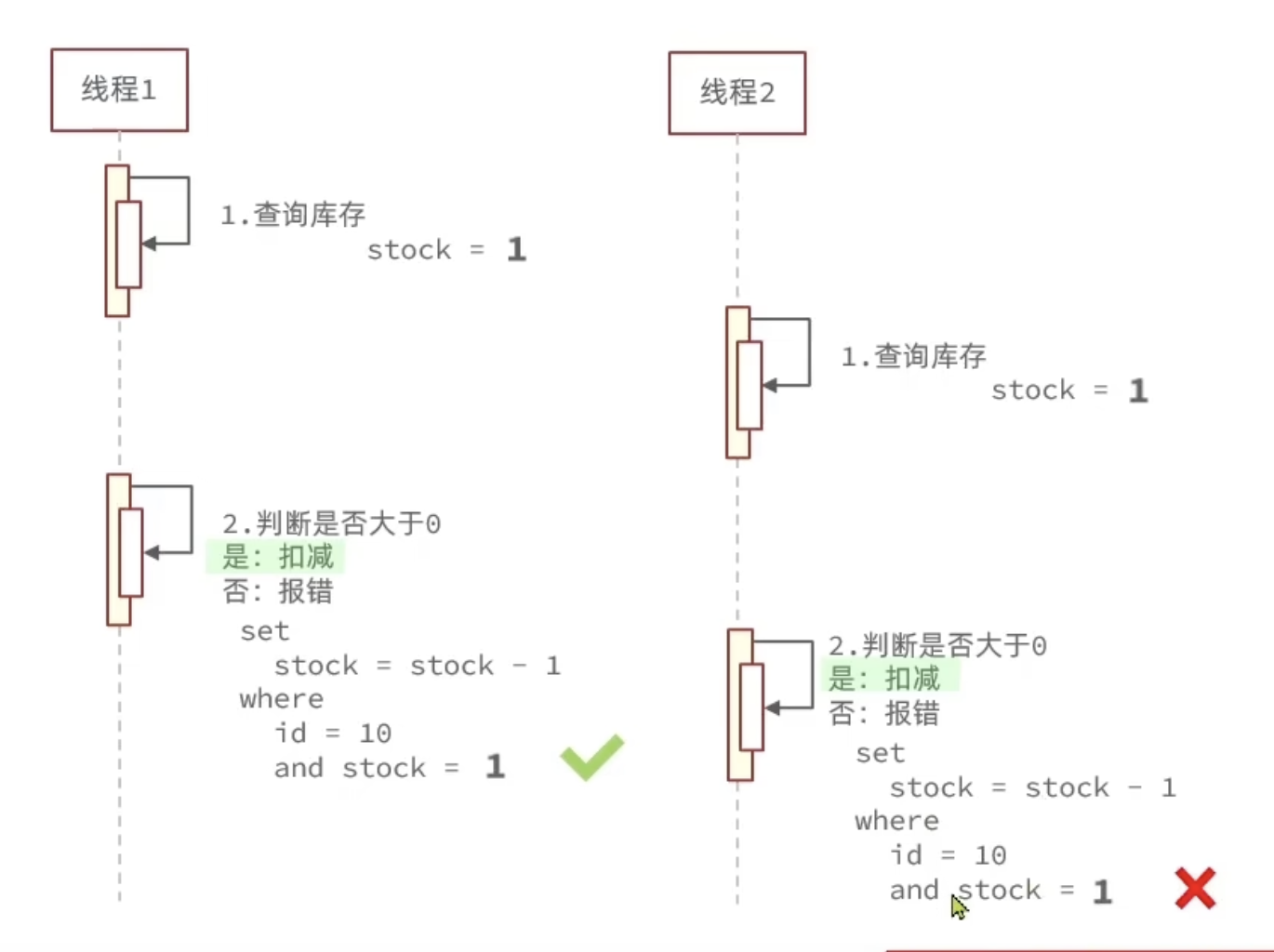
类似版本号法,直接比较数据在查询到和修改时是否一致。
但是这样会导致大量并发场景下,只有少数用户可以成功。因为剩余的优惠券票数很难不在查询到修改之间被别的线程修改。因此,在修改数据时直接判断数据是否合法即可(比如这里在 update 时只需判断 where stock > 0 ),把锁交给数据库的行锁。
一人一单
防止同一个人一直抢单而引发的并发问题
对同一个用户上锁(userId)
细节:
1 | synchronized(userId.tostring().intern()){...} |
如果去掉.intern(),userId.toString()每次会生成新的字符串对象(比如两次123.toString()得到两个不同的"123"对象),导致synchronized锁失效(锁了不同对象,无法保证串行);
.intern() 强制让相同内容的字符串复用常量池中的同一个对象,确保锁对象唯一。
推荐方案
1. 单 JVM 场景(替代.intern())
用ConcurrentHashMap维护锁对象,避免常量池膨胀:
1 | // 全局维护用户ID对应的锁对象 |
2. 分布式场景(跨 JVM)
用 Redis 分布式锁(如 Redisson)按userId加锁:
1 | // Redisson客户端 |
分布式锁
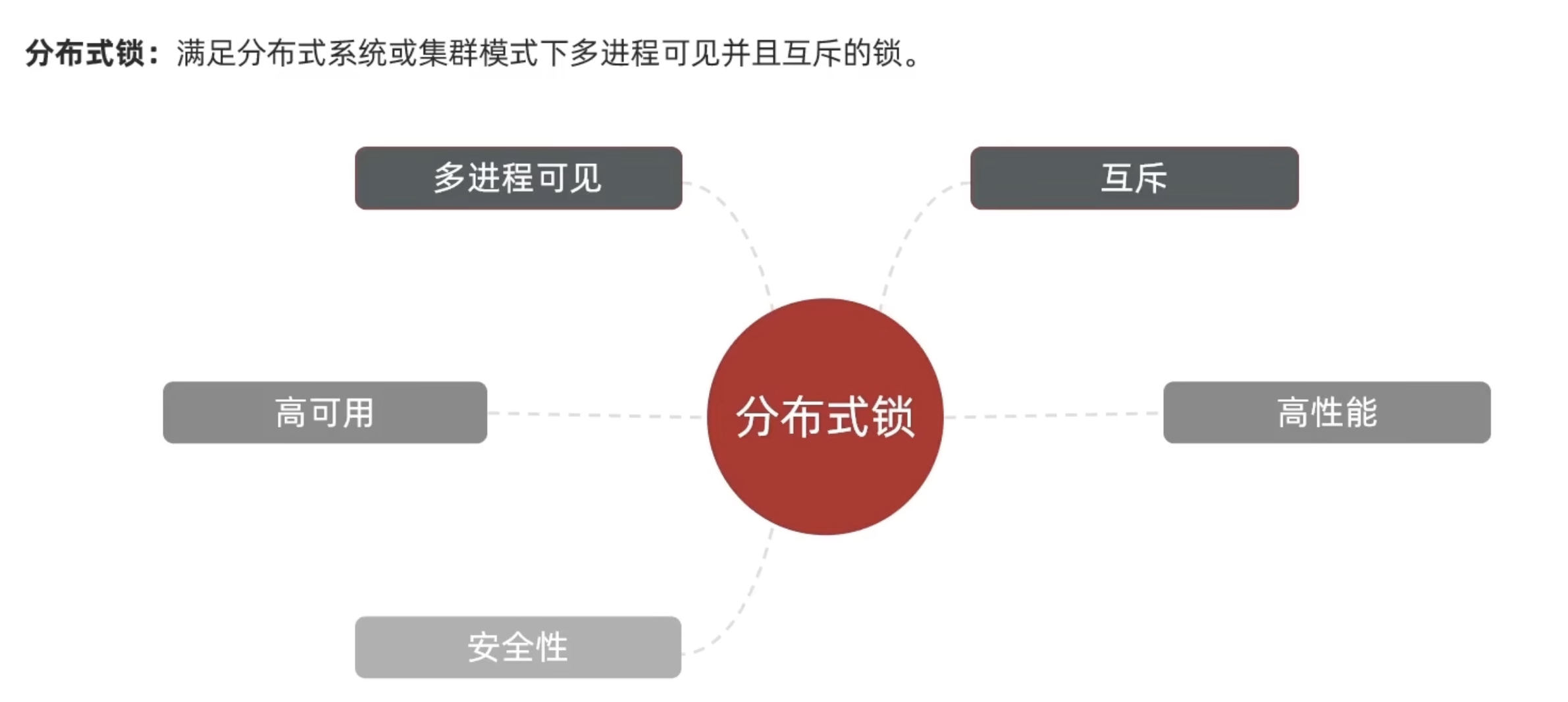
满足分布式系统或集群模式下多进程可见并互斥的锁
分布式锁的核心是实现多进程之间互斥,而满足这一点的方式有很多,常见的有三种:
| MySQL | Redis | Zookeeper | |
|---|---|---|---|
| 互斥 | 利用 mysql 本身的互斥锁机制 | 利用 setnx 这样的互斥命令 | 利用节点的唯一性和有序性实现互斥 |
| 高可用 | 好 | 好 | 好 |
| 高性能 | 一般 | 好 | 一般 |
| 安全性 | 断开连接,自动释放锁 | 利用锁超时时间,到期释放 | 临时节点,断开连接自动释放 |
基于 setnx 实现的分布式锁
1.获取锁
1 | # NX为互斥, EX 是设置超时时间 |
要存入线程标识
2.释放锁
1 | # 删除锁 |
释放锁应检查是否为自己设置的锁(锁标识,通常在 value 表示)
原子性问题
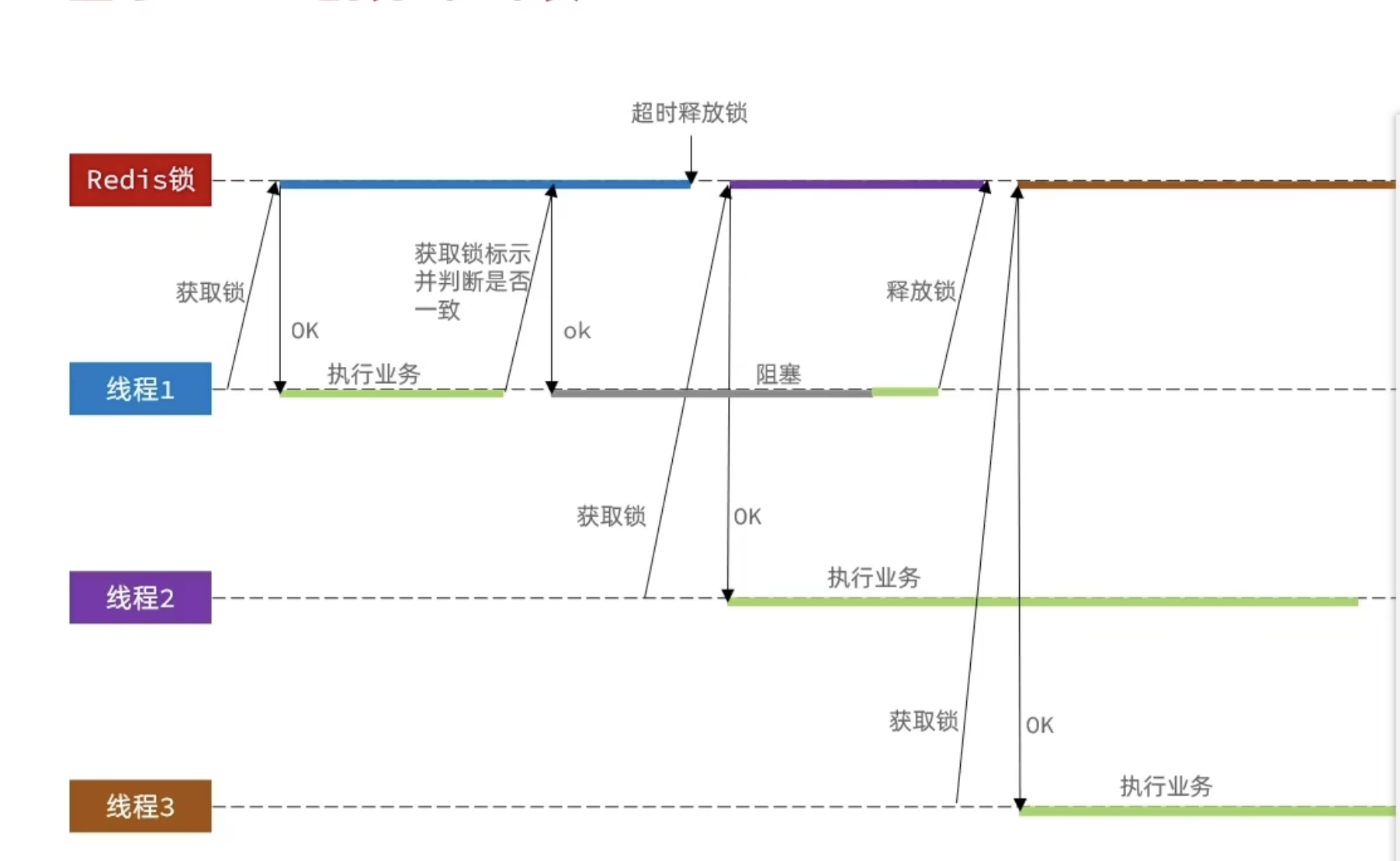
阻塞(可能由 GC 导致)会导致一个线程在判断锁和释放锁之间被其他线程获取到锁。此时可以用Lua脚本保持多个命令执行的原子性。
编写脚本:
1 | -- 锁的key |
保存为unlock.lua
使用:
1 | private static final DefaultRedisScript<Long> UNLOCK_SCRIPT; |
基于 setnx 实现的分布式锁存在下面的问题:
不可重入
同一个线程无法多次获取同一把锁
不可重试
获取锁只尝试一次就返回 false,没有重试机制
超时释放
锁超时释放虽然可以避免死锁,但如果是业务执行耗时较长,也会导致锁释放,存在安全隐患
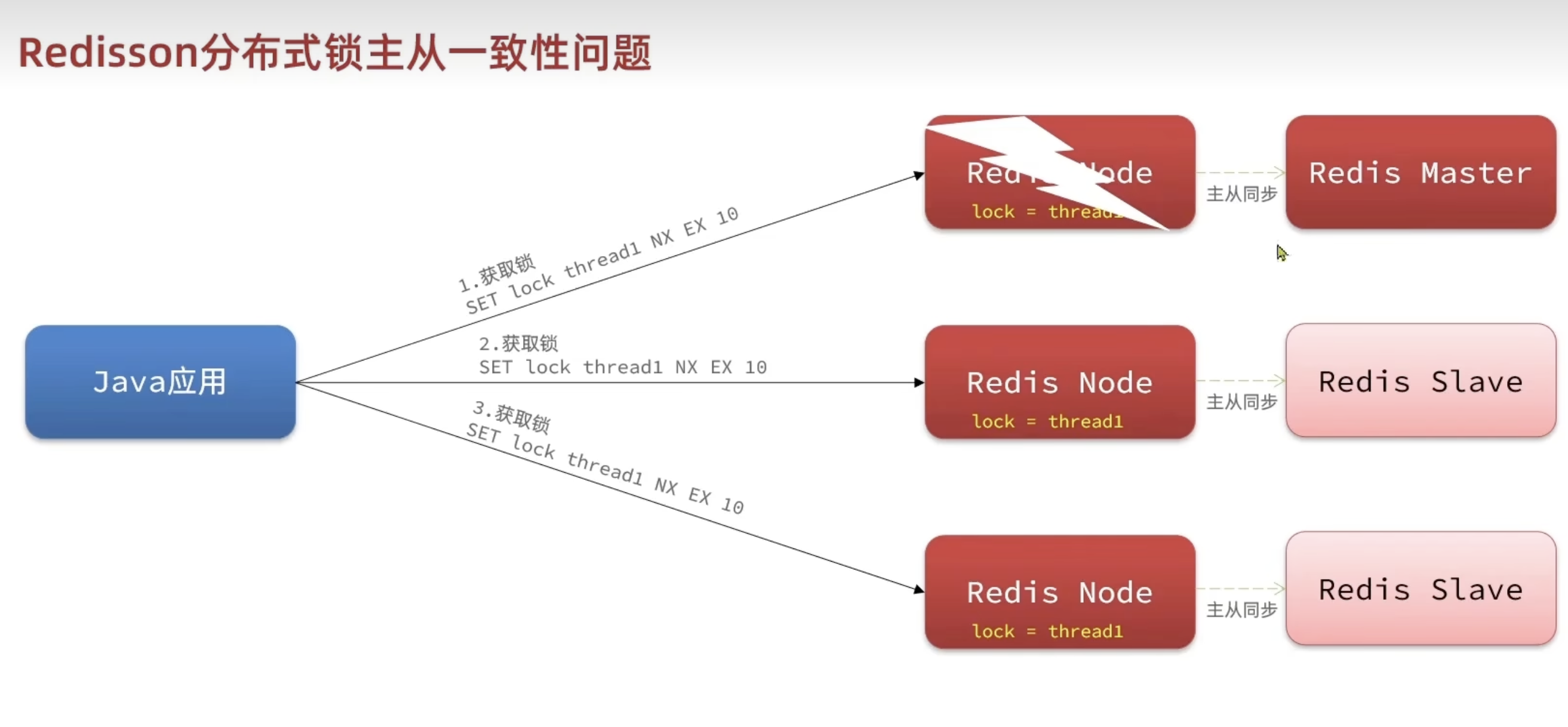
主从一致性
如果 Redis 提供了主从集群,主从同步存在延迟,当主宕机时,如果从并未同步主中的锁数据,则会出现锁实现的问题
基于Redisson 实现分布式锁
Redisson 是一个在 Redis 的基础上实现的 Java 驻内存数据网格(In-Memory Data Grid)。它不仅提供了一系列的分布式的 Java 常用对象,还提供了许多分布式服务,其中就包含了各种分布式锁的实现。
8. 分布式锁(Lock)和同步器(Synchronizer)
- 8.1. 可重入锁(Reentrant Lock)
- 8.2. 公平锁(Fair Lock)
- 8.3. 联锁(MultiLock)
- 8.4. 红锁(RedLock)
- 8.5. 读写锁(ReadWriteLock)
- 8.6. 信号量(Semaphore)
- 8.7. 可过期性信号量(PermitExpirableSemaphore)
- 8.8. 闭锁(CountDownLatch)
官网地址:https://redisson.org
GitHub 地址:https://github.com/redisson/redisson
使用
建议单独引入依赖和配置 Redisson,直接在springboot-starter 引入会覆盖 Spring 对于 redis 的默认配置。
1. 引入依赖:
1 | <dependency> |
2. 配置 Redisson 客户端:
1 |
|
3. 使用 Redisson 的分布式锁
1 |
|
流程图
 获取锁的 Lua 脚本:
获取锁的 Lua 脚本:
1 | local key = KEYS[1]; -- 锁的key |
释放锁的 lua 脚本:
1 | local key = KEYS[1]; -- 锁的key |

Redisson分布式锁原理:
• 可重入:利用hash结构记录线程id和重入次数
• 可重试:利用信号量和PubSub功能实现等待、唤醒,获取锁失败的重试机制
• 超时续约:利用watchDog,每隔一段时间(releaseTime/3),重置超时时间
一、Redisson 分布式锁核心类与整体架构
Redisson 分布式锁的核心实现类是 org.redisson.RedissonLock(实现 RLock 接口),底层基于 Redis Hash 结构 + Lua 脚本(保证原子性),结合 Redis PubSub、定时任务(WatchDog)实现可重试、超时续约,最终解决原生 SETNX 锁的缺陷。
以下是核心特性的源码片段 + 原理拆解:
二、可重入:基于 Redis Hash 结构记录线程 ID 和重入次数
1. 核心源码(获取锁的 Lua 脚本 + 调用逻辑)
(1)获取锁的 Lua 脚本(RedissonLock#tryAcquireAsync 核心逻辑)
1 | // RedissonLock中获取锁的Lua脚本(关键片段) |
(2)释放锁的 Lua 脚本(RedissonLock#unlockAsync 核心逻辑)
1 | String UNLOCK_SCRIPT = "local key = KEYS[1]; " + |
2. 可重入原理
数据结构
Redis 中锁的 Key 是业务锁名(如anyLock),Value 是 Hash 结构:
Field:线程唯一标识(格式:Redisson客户端ID:线程ID,如uuid-123:101);Value:该线程的重入次数。
核心逻辑
- 第一次获取锁:Redis 中不存在该锁 Key →
hset key 线程ID 1,并设置过期时间; - 重入获取锁:Redis 中已存在该锁 Key,且 Hash 的 Field 包含当前线程 ID →
hincrby key 线程ID 1(重入次数 + 1),重置过期时间; - 释放锁:
hincrby key 线程ID -1(重入次数 - 1),若次数 > 0 则仅重置过期时间,若次数 = 0 则删除锁 Key,并发布锁释放消息。
- 第一次获取锁:Redis 中不存在该锁 Key →
三、可重试:基于 PubSub + 信号量实现等待 - 唤醒重试
1. 核心源码(获取锁失败的重试逻辑)
1 | // RedissonLock#acquireFailedAsync :获取锁失败后订阅锁释放消息,等待重试 |
2. 可重试原理
Redisson 的 “可重试” 不是无脑循环重试,而是优雅的等待 - 唤醒机制,核心步骤:
- 获取锁失败后,通过 Redis 的 PubSub 功能订阅该锁的 “释放消息通道”;
- 创建一个信号量(Semaphore),让当前线程阻塞等待(设置最大等待时间,避免永久阻塞);
- 当其他线程释放该锁时,会执行
PUBLISH命令发布锁释放消息; - 订阅到消息的线程被唤醒,重新尝试调用
tryAcquireOnceAsync获取锁; - 若超过最大等待时间仍未获取到锁,则取消订阅并返回失败。
这种机制避免了 “自旋重试” 的 CPU 空耗,实现了高效的重试逻辑。
四、超时续约:基于 WatchDog(看门狗)定时重置过期时间
1. 核心源码(WatchDog 续约逻辑)
1 | // RedissonLock#scheduleExpirationRenewal :启动WatchDog定时续约 |
2. 超时续约原理
WatchDog(看门狗)是 Redisson 内置的定时续约机制,核心规则:
- 触发条件:当调用
tryLock未指定leaseTime(即leaseTime=-1)时,自动启用 WatchDog; - 续约周期:默认
internalLockLeaseTime=30秒(锁的初始过期时间),每隔30/3=10秒执行一次续约; - 续约逻辑:通过 Lua 脚本判断锁仍被当前线程持有 → 执行
EXPIRE命令重置锁的过期时间为 30 秒; - 停止条件:当线程释放锁(调用
unlock)时,会从EXPIRATION_RENEWAL_MAP中移除该锁的续约任务,WatchDog 停止; - 作用:避免 “业务执行时间> 锁过期时间” 导致的锁提前释放,保证业务执行期间锁始终有效。
Redisson 分布式锁核心流程总结
- 获取锁:调用
tryLock→ 执行获取锁的 Lua 脚本 → 成功则启动 WatchDog → 失败则订阅锁释放消息 + 信号量等待重试; - 重入锁:Lua 脚本检测到当前线程已持有锁 → 重入次数 + 1,重置过期时间;
- 续约锁:WatchDog 每隔 10 秒执行续约 Lua 脚本,重置锁过期时间;
- 释放锁:执行释放锁的 Lua 脚本 → 重入次数 - 1 → 次数 = 0 则删除锁 Key + 发布释放消息 → 停止 WatchDog;
- 重试获取:订阅到释放消息的线程被唤醒 → 重新执行获取锁逻辑。
这套机制完美解决了原生 SETNX 锁 “不可重入、不可重试、超时释放” 的三大缺陷,是分布式锁的工业级实现。
但还没解决主从一致性问题
MultiLock
MultiLock 是 Redisson 提供的多 Redis 节点 / 多锁的 “组合锁”,核心规则是:
- 同时获取所有子锁,才视为获取联锁成功;
- 只要有一个子锁获取失败,就会释放已获取的子锁;
- 释放联锁时,会同时释放所有子锁。
- 缺陷:运维成本高、实现复杂
使用:
1 | private RedissonClient redissonClient; |
MultiLock 核心源码与逻辑拆解
Redisson MultiLock 的核心实现类是 org.redisson.MultiLock(实现RLock接口),以下是核心逻辑的源码片段:
1. 核心属性:维护子锁列表
1 | public class MultiLock implements RLock { |
2. 获取联锁的核心逻辑(tryLock方法)
MultiLock 获取锁的核心是 “同时尝试获取所有子锁,失败则回滚”,关键步骤:
- 为每个子锁分配 “等待时间”;
- 依次尝试获取子锁;
- 若子锁获取失败的数量超过
locksLimit,则释放已获取的子锁,返回失败; - 若所有子锁都获取成功,返回成功。
1 |
|
3. 释放联锁的核心逻辑(unlock方法)
释放联锁时,会遍历所有子锁,依次释放(即使部分子锁释放失败,也会尝试释放所有子锁):
1 |
|
4. 超时续约(WatchDog)逻辑
MultiLock 的超时续约逻辑与普通 RLock 一致:
- 若未指定
leaseTime,则为每个子锁单独启动 WatchDog; - 每个子锁的 WatchDog 独立续约,保证所有子锁的过期时间都被重置。
MultiLock 的核心特点
- 强一致性:必须同时获取所有子锁才成功,避免单节点故障导致锁失效;
- 自动回滚:获取子锁失败时,自动释放已获取的子锁,避免 “锁残留”;
- 独立续约:每个子锁的 WatchDog 独立工作,保证所有子锁的有效性;
- 高可用:适用于 Redis 集群场景,提升锁的可靠性。
改进秒杀业务,提高并发性能
需求:
① 新增秒杀优惠券的同时,将优惠券信息保存到Redis中
②基于Lua脚本,判断秒茶库存、一人一单,决定用户是否抢购成功
③ 如果抢购成功,将优惠券id和用户id封装后存入阻塞队列
④ 开启线程任务,不断从阻塞队列中获取信息,实现异步下单功能
核心代码:
1 | private BlockingQueue<VoucherOrder> orderTasks = new ArrayBlockingQueue<>(capacity: 1024 * 1024); |
秒杀业务的优化思路
① 先利用Redis完成库存余量、一人一单判断,完成抢单业务
② 再将下单业务放入阻塞队列,利用独立线程异步下单
基于阻塞队列的异步秒杀存在哪些问题?
• 内存限制问题
• 数据安全问题
使用 Redis 消息队列实现异步秒杀
Redis提供了三种不同的方式来实现消息队列:
• list结构:基于List结构模拟消息队列 (LPUSH结合 BRPOP 或者 BLPOP 结合 RPUSH)
• PubSub:基本的点对点消息模型
• Stream: 比较完善的消息队列模型
基于PubSub的消息队列
Pubsub(发布订阅)是Redis2.0版本引入的消息传递模型。顾名思义,消费者可以订阅一个或多个channel,生产者
向对应channel发送消息后,所有订阅者都能收到相关消息。
- SUBSCRIBE channel [channel]:订阅一个或多个频道
- PUBLISH channel msg:向一个频道发送消息
- PSUBSCRIBE pattern[pattern]:订阅与pattern格式匹配的所有频道
基于PubSub的消息队列有哪些优缺点?
优点:
• 采用发布订阅模型,支持多生产、多消费
缺点:
• 不支持数据持久化
• 无法避免消息丢失
• 消息堆积有上限,超出时数据丢失
基于 Stream 的消息队列
Stream 是 Redis 5.0 新增的数据类型,专门用于实现功能完善的消息队列(支持消息持久化、消费组、消息确认等特性)。
 生产者发消息:
生产者发消息:
1 | XADD key [NOMKSTREAM] [MAXLEN|MINID [=|~] threshold] [LIMIT count] *|ID field value [field value ...] |
各参数的作用(对应图中标记):
key:消息队列的名称(如示例中的users);NOMKSTREAM:可选参数,若队列不存在则不自动创建(默认是自动创建);MAXLEN:设置队列的最大消息数量(避免队列过大占用内存);\*|ID:消息的唯一 ID,*代表由 Redis 自动生成(格式为 “时间戳-递增数字”,如1644804662707-0);field value:消息内容(以 key-value 键值对形式存储,称为Entry)。
示例命令:
1 | XADD users * name jack age 21 |
含义是:
- 创建名为
users的 Stream 队列(不存在则自动创建); - 向队列中发送一条消息,内容是
{name: "jack", age: "21"}; - 消息 ID 由 Redis 自动生成(返回结果
1644805700523-0就是这条消息的 ID)。
消费者读消息: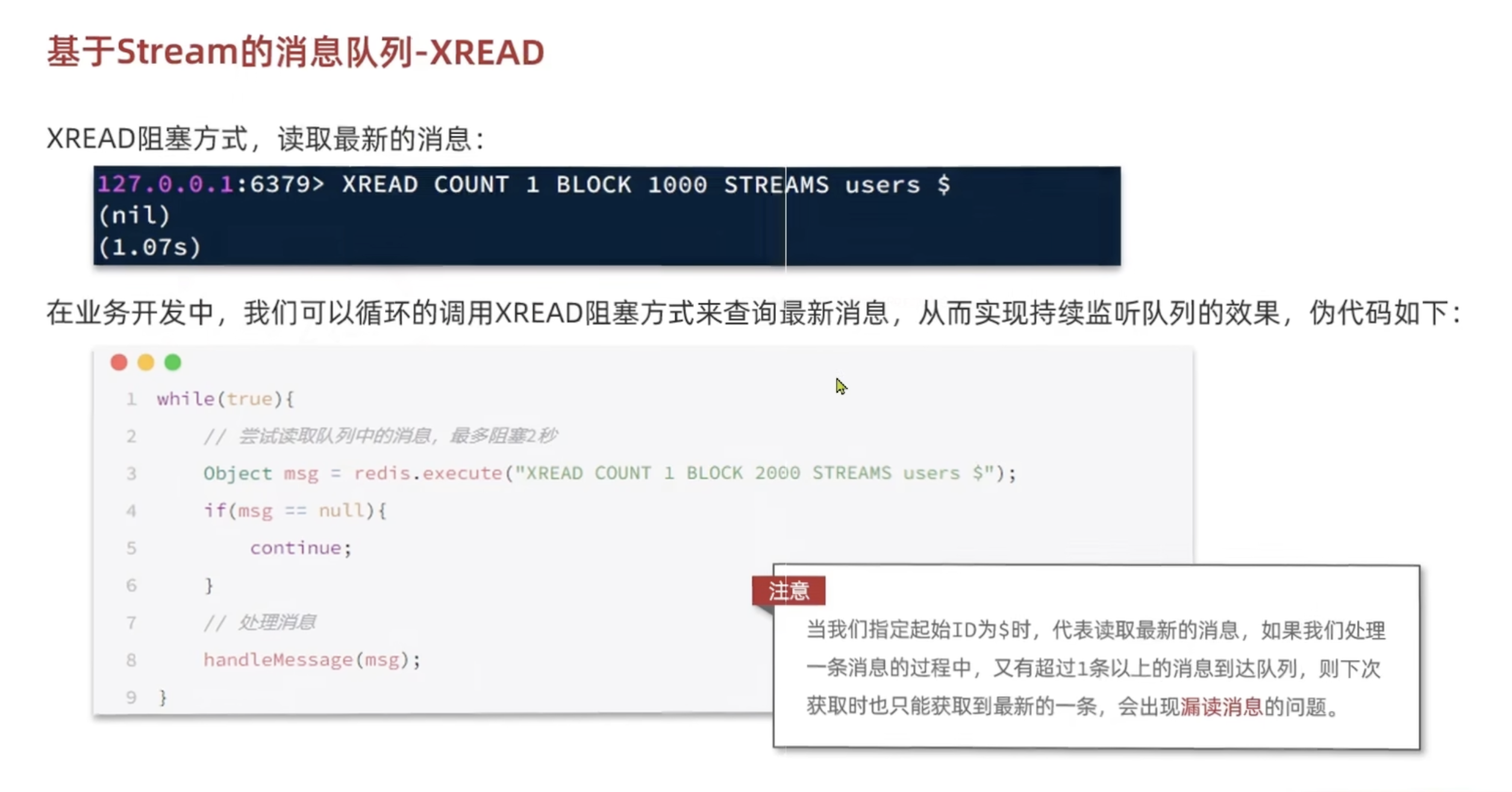
XREAD是 Redis Stream 中读取消息的命令,支持阻塞式读取(类似消息队列的 “监听”),用于从 Stream 队列中获取消息。
1 | XREAD COUNT 1 BLOCK 1000 STREAMS users $ |
各参数含义:
COUNT 1:每次最多读取 1 条消息;BLOCK 1000:阻塞等待 1000 毫秒(若队列无消息,会等待 1 秒后返回nil);STREAMS users:指定要读取的 Stream 队列名称是users;$:起始消息 ID,$代表 “读取队列中最新的消息”(仅读取命令执行后新产生的消息)。
命令执行结果是(nil),说明 1 秒内队列无新消息,阻塞超时后返回空。
业务中实现 “持续监听” 的伪代码
通过while(true)循环调用阻塞式XREAD,实现持续监听队列的效果:
1 | while(true){ |
关键注意事项
当起始 ID 用$时,仅会读取 “命令执行后产生的最新消息”,存在漏读风险:
- 若处理一条消息的过程中,队列新增了多条消息,下次
XREAD只会读取 “最新的那一条”,中间的消息会被跳过。
XREAD是 Stream 的基础消费命令,适合简单的 “单消费者监听最新消息” 场景,但起始 ID 用$会漏读消息,实际生产中通常会结合 “消费组(Consumer Group)”+“消息 ID 续传” 来避免漏读。
消费者组
消费者组是将多个消费者归为一组、共同监听同一个 Stream 队列的机制,主要有 3 个关键特性:
1. 消息分流
队列中的消息会分配给组内不同的消费者(而非重复消费),实现消息的 “负载均衡”,提升整体消息处理的速度。
- 比如队列有 10 条消息,组内有 2 个消费者,会大致平分消息(各处理 5 条),避免单消费者的性能瓶颈。
2. 消息标示
消费者组会维护一个 “消费进度标示”(记录组内最后一个被处理的消息 ID),即使消费者宕机重启,也会从标示的位置继续读取消息,确保每一条消息都能被消费,不会出现漏读。
- 解决了
XREAD用$(读最新消息)导致的漏读问题。
3. 消息确认
消费者获取消息后,消息会进入 pending 状态(待处理) 并存入pending-list;只有当消费者处理完消息后,通过XACK命令确认消息,该消息才会从pending-list中移除。
- 若消费者处理消息时宕机,未确认的消息会留在
pending-list中,后续可重新分配给组内其他消费者处理,避免消息丢失。
创建消费者组:
1 | XGROUP CREATE key groupName ID [MKSTREAM] |
- key:队列名称
- groupName:消费者组名称
- ID:起始 ID 标示,
$代表队列中最后一个消息,0则代表队列中第一个消息 - MKSTREAM:队列不存在时自动创建队列
其它常见命令:
1 | # 删除指定的消费者组 |
从消费者组读取消息:
1 | XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] ID [ID ...] |
- group:消费组名称
- consumer:消费者名称,如果消费者不存在,会自动创建一个消费者
- count:本次查询的最大数量
- BLOCK milliseconds:当没有消息时最长等待时间
- NOACK:无需手动 ACK,获取到消息后自动确认
- STREAMS key:指定队列名称
- ID:获取消息的起始 ID:
">>":从下一个未消费的消息开始- 其它:根据指定 id 从 pending-list 中获取已消费但未确认的消息,例如
0,是从 pending-list 中的第一个消息开始
确认消息:
1 | XACK group ID [ID ...] |
标记一个待处理(pending)的消息为正确的消息。
读还未确认的消息:
1 | XPENDING group ID [ID ...] |
读取所有未消费的消息。
示例 Java 伪代码:
1 | while(true){ |
总结:
| List | PubSub | Stream | |
|---|---|---|---|
| 消息持久化 | 支持 | 不支持 | 支持 |
| 阻塞读取 | 支持 | 支持 | 支持 |
| 消息堆积处理 | 受限于内存空间,可以利用多消费者加快处理 | 受限于消费者缓冲区 | 受限于队列长度,可以利用消费者组提高消费速度,减少堆积 |
| 消息确认机制 | 不支持 | 不支持 | 支持 |
| 消息回溯 | 不支持 | 不支持 | 支持 |
Redis 集群
持久化
RDB
RDB 全称 Redis Database Backup file(Redis 数据备份文件),也被叫做 Redis 数据快照。简单来说就是把内存中的所有数据都记录到磁盘中。当 Redis 实例故障重启后,从磁盘读取快照文件,恢复数据。默认在服务停止时,自动进行 RDB。
快照文件称为 RDB 文件,默认是保存在当前运行目录。
1 | [root@localhost ~]# redis-cli |
Redis 内部有触发 RDB 的机制,可以在 redis.conf 文件中找到,格式如下:
1 | # 900秒内, 如果至少有1个key被修改, 则执行bgsave , 如果是save "" 则表示禁用RDB |
RDB 的其它配置也可以在 redis.conf 文件中设置:
1 | # 是否压缩 ,建议不开启, 压缩也会消耗cpu, 磁盘的话不值钱 |
bgsave 开始时会 fork 主进程得到子进程,子进程共享主进程的内存数据。完成 fork 后读取内存数据并写入 RDB 文件。
fork 采用的是 copy-on-write 技术:
- 当主进程执行读操作时,访问共享内存;
- 当主进程执行写操作时,则会拷贝一份数据,执行写操作。

流程:
- 主进程通过
fork创建子进程,复制主进程的页表(不复制实际内存数据); - 子进程通过页表访问物理内存中的共享数据,执行读操作并写入 RDB 文件;
- 主进程执行读操作:直接访问共享物理内存;
- 主进程执行写操作:拷贝对应数据的副本,在副本上执行写操作(不影响子进程读取的原始数据);
- 子进程完成数据读取后,将新 RDB 文件写入磁盘并替换旧文件
AOF
AOF全称为Append Only File(追加文件)。Redis处理的每一个写命令都会记录在AOF文件,可以看做是命令日志文件。
AOF 默认是关闭的,需要修改redis.conf配置文件来开启 AOF:
1 | # 禁用RDB |
AOF 的命令记录的频率也可以通过redis.conf文件来配:
1 | # 表示每执行一次写命令,立即记录到AOF文件 |
AOF 刷盘策略对比
| 配置项 | 刷盘时机 | 优点 | 缺点 |
|---|---|---|---|
| Always | 同步刷盘 | 可靠性高,几乎不丢数据 | 性能影响大 |
| everysec | 每秒刷盘 | 性能适中 | 最多丢失 1 秒数据 |
| no | 操作系统控制 | 性能最好 | 可靠性较差,可能丢失大量数据 |
因为是记录命令,AOF文件会比RDB文件大的多。而且AOF会记录对同一个key的多次写操作,但只有最后一次写操作才
有意义。通过执行bgrewriteaof命令,可以让AOF文件执行重写功能,用最少的命令达到相同效果。
Redis 也会在触发阈值时自动去重写 AOF 文件。阈值也可以在 redis.conf 中配置:
1 | # AOF文件比上次文件 增长超过多少百分比则触发重写 |
RDB 和 AOF 各有自己的优缺点,如果对数据安全性要求较高,在实际开发中往往会结合两者来使用。
| 对比项 | RDB | AOF |
|---|---|---|
| 持久化方式 | 定时对整个内存做快照 | 记录每一次执行的命令 |
| 数据完整性 | 不完整,两次备份之间会丢失 | 相对完整,取决于刷盘策略 |
| 文件大小 | 会有压缩,文件体积小 | 记录命令,文件体积很大 |
| 宕机恢复速度 | 很快 | 慢 |
| 数据恢复优先级 | 低,因为数据完整性不如 AOF | 高,因为数据完整性更高 |
| 系统资源占用 | 高,大量 CPU 和内存消耗 | 低,主要是磁盘 IO 资源但 AOF 重写时会占用大量 CPU 和内存资源 |
| 使用场景 | 可以容忍数分钟的数据丢失,追求更快的启动速度 | 对数据安全性要求较高常见 |
单独用 RDB 可能丢失快照间隔内的大量数据,单独用 AOF 恢复速度慢且文件体积大。Redis 4.0 + 支持 RDB+AOF 混合持久化,既保留 RDB 快速恢复的优势,又兼顾 AOF 数据一致性的优点。
RDB+AOF 混合持久化
单独使用 RDB 可能会丢失快照间隔的大量数据,单独用 AOF 恢复速度慢且文件体积大。使用RDB+AOF 混合持久化,既保留 RDB 快速恢复的优势,又兼顾 AOF 数据一致性的优点。
RDB+AOF 混合持久化的工作原理
1. 核心机制
混合持久化开启后,AOF 文件由两部分组成:
- 前半部分:RDB 格式的全量数据(快照);
- 后半部分:AOF 格式的增量命令(从 RDB 快照生成后到当前的所有写命令)。
2. 执行流程
① 触发 AOF 重写时(手动bgrewriteaof/ 自动触发),Redis fork 子进程;
② 子进程先将当前内存数据以 RDB 格式写入新 AOF 文件;
③ 主进程将重写期间产生的新写命令,以 AOF 格式追加到新 AOF 文件;
④ 重写完成后,替换旧 AOF 文件;
⑤ 后续的写命令仍以 AOF 格式追加到混合文件的尾部。
3. 恢复流程
Redis 重启时,优先加载 AOF 文件:
① 先加载 AOF 文件中的 RDB 部分,快速恢复全量数据;
② 再加载 AOF 文件中的增量命令部分,补全最新数据;
③ 若 AOF 文件损坏,降级加载 RDB 文件(兜底)。
总结:
Redis 混合持久化(RDB+AOF)是生产环境的主流方案,核心是通过 AOF 文件整合 RDB 全量快照和 AOF 增量命令,既解决了纯 RDB 数据丢失多的问题,又解决了纯 AOF 恢复慢、文件大的问题。配置上只需开启aof-use-rdb-preamble yes,结合合理的刷盘和重写阈值,就能在性能和数据一致性之间取得平衡。
Redis 主从
主 master、从 slave/replica。主节点写,子节点读
要配置主从可以使用replicaof或者slaveof(5.0 以前)命令。
有临时和永久两种模式:
修改配置文件(永久生效)
- 在
redis.conf中添加一行配置:slaveof <masterip> <masterport>
- 在
使用 redis-cli 客户端连接到 redis 服务,执行 slaveof 命令(重启后失效):
1
slaveof <masterip> <masterport>
注意:在 5.0 以后新增命令replicaof,与slaveof效果一致。
数据同步原理
全量同步
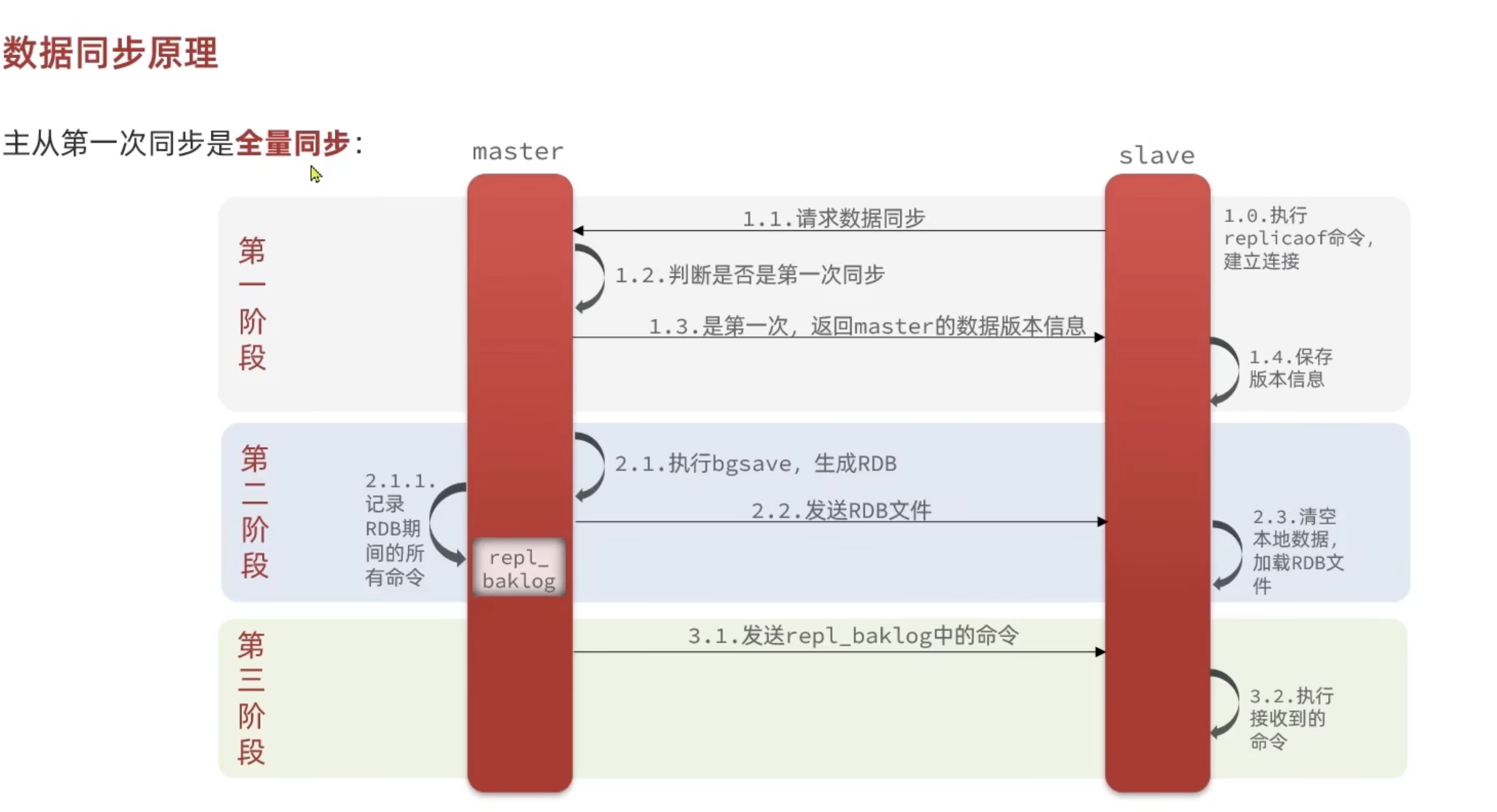
主从刚建立连接(slave 执行replicaof命令),此时 slave 无数据,需要从 master 全量同步。
第一阶段:建立同步请求与版本确认
- slave 端:执行
replicaof命令,向 master 发起数据同步请求; - master 端:判断是第一次同步,返回自己的数据版本信息(用于后续校验);
- slave 端:保存 master 的版本信息,准备接收数据。
第二阶段:生成并传输全量数据(RDB)
- master 端:执行
bgsave生成 RDB 快照文件,同时将生成 RDB 期间的新写命令记录到repl_backlog(复制积压缓冲区); - master 端:将 RDB 文件发送给 slave;
- slave 端:清空本地原有数据,加载接收到的 RDB 文件,完成全量数据恢复。
第三阶段:同步增量命令(补全 RDB 生成期间的新数据)
- master 端:将
repl_backlog中记录的 “RDB 生成期间的新命令” 发送给 slave; - slave 端:执行这些增量命令,确保数据与 master 完全一致。
简述全量同步的流程?
- slave节点请求增量同步
- master节点判断replid,发现不一致,拒绝增量同步
- master将完整内存数据生成RDB,发送RDB到slave
- slave清空本地数据,加载master的RDB
- master将RDB期间的命令记录在repL_baklog,并持续将log中的命令发送给slave
- slave执行接收到的命令,保持与master之间的同步
增量同步

slave 之前已与 master 完成全量同步,本次是重启后重新连接,仅需同步 “离线期间 master 新增的命令”。
第一阶段:同步请求与身份验证
slave 端:重启后向 master 发送
1
psync replid offset
请求;
replid:master 的标识(唯一 ID),用于确认是否是之前的同一个 master;offset:slave 最后一次同步到的 “命令偏移量”(记录自己同步到了哪个位置)。
master 端:判断
replid是否与自己的一致(确认是同一个主节点);master 端:回复
continue,表示可以执行增量同步。
第二阶段:同步增量命令
- master 端:从
repl_backlog(复制积压缓冲区)中,读取offset之后的所有新命令; - master 端:将这些增量命令发送给 slave;
- slave 端:执行接收到的增量命令,完成数据同步,使自己的数据与 master 保持一致。
repl_baklog大小有上限,写满后会覆盖最早的数据。如果slave断开时间过久,导致数据被覆盖,则无法实现增量同步,只能再次全量同步。
优化 Redis 主从集群:
- 在 master 中配置
repl-diskless-sync yes启用无磁盘复制,避免全量同步时的磁盘 IO。 - Redis 单节点上的内存占用不要太大,减少 RDB 导致的过多磁盘 IO
- 适当提高
repl_backlog的大小,发现 slave 宕机时尽快实现故障恢复,尽可能避免全量同步 - 限制一个 master 上的 slave 节点数量,如果实在是太多 slave,则可以采用主 - 从 - 从链式结构,减少 master 压力
Redis 哨兵
Redis 提供了哨兵(Sentinel)机制来实现主从集群的自动故障恢复。哨兵的结构和作用如下:
- 监控:Sentinel 会不断检查您的 master 和 slave 是否按预期工作
- 自动故障恢复:如果 master 故障,Sentinel 会将一个 slave 提升为 master。当故障实例恢复后也以新的 master 为主
- 通知:Sentinel 充当 Redis 客户端的服务发现来源,当集群发生故障转移时,会将最新信息推送给 Redis 的客户端
Sentinel 的作用
1.服务状态监控
Sentinel 基于心跳机制监测服务状态,每隔 1 秒向集群的每个实例发送 ping 命令:
- 主观下线:如果某 sentinel 节点发现某实例未在规定时间响应,则认为该实例主观下线。
- 客观下线:若超过指定数量(quorum)的 sentinel 都认为该实例主观下线,则该实例客观下线。quorum 值最好超过 Sentinel 实例数量的一半。
2.选举新的 master
一旦发现 master 故障,sentinel 需要在 slave 中选择一个作为新的 master,选择依据是这样的:
- 首先会判断 slave 节点与 master 节点断开时间长短,如果超过指定值(down-after-milliseconds * 10)则会排除该 slave 节点
- 然后判断 slave 节点的 slave-priority 值( 意为“从节点” 的 “优先级权重”),越小优先级越高,如果是 0 则永不参与选举
- 如果 slave-priority 一样,则判断 slave 节点的 offset 值,越大说明数据越新,优先级越高
- 最后是判断 slave 节点的运行 id 大小,越小优先级越高。
3.故障转移
当选中了其中一个 slave 为新的 master 后(例如 slave1),故障的转移的步骤如下:
- sentinel 给备选的 slave1 节点发送 slaveof no one 命令,让该节点成为 master
- sentinel 给所有其它 slave 发送 slaveof 192.168.150.101 7002 命令,让这些 slave 成为新 master 的从节点,开始从新的 master 上同步数据。
- 最后,sentinel 将故障节点标记为 slave,当故障节点恢复后会自动成为新的 master 的 slave 节点
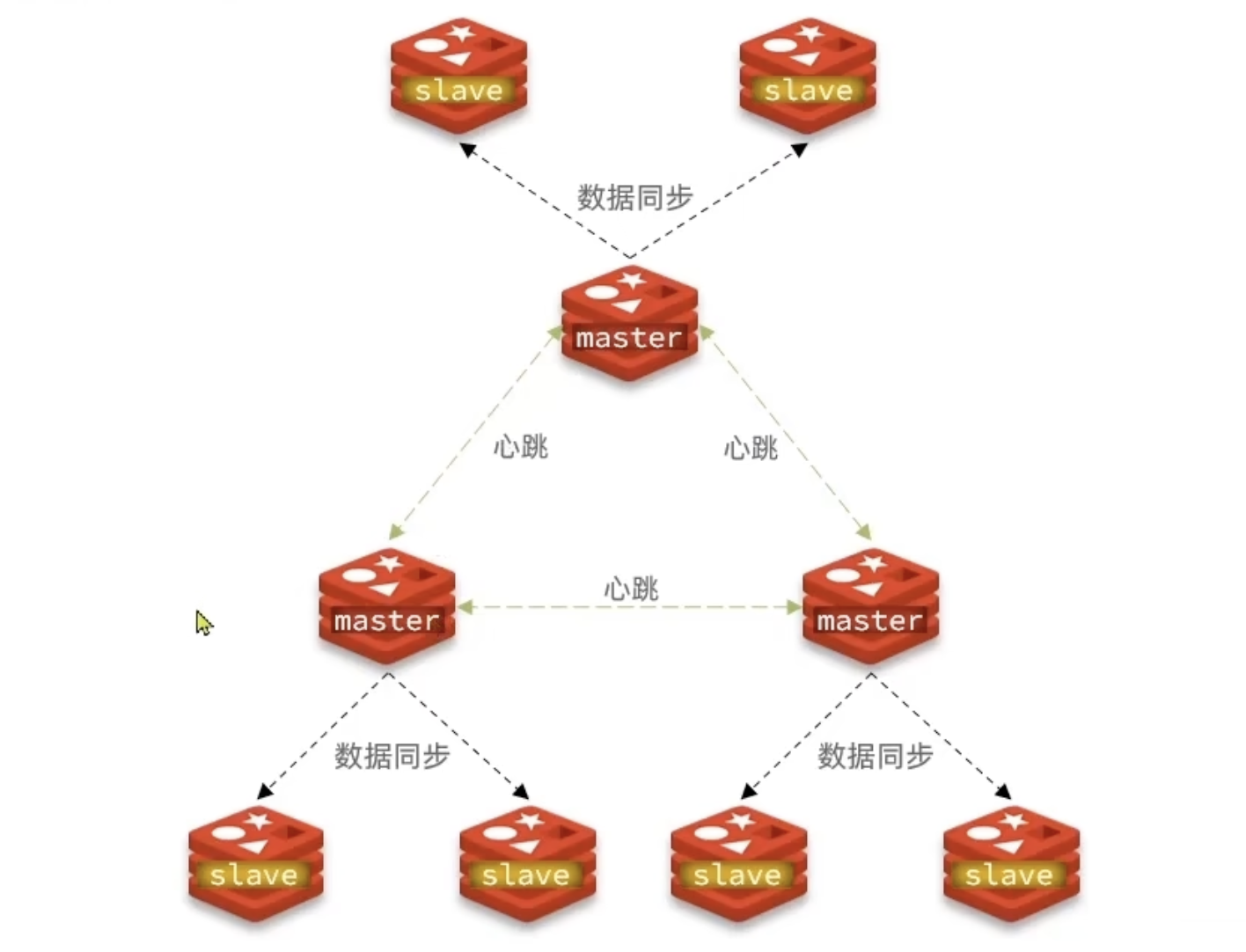
Redis 分片集群
主从和哨兵可以解决高可用、高并发读的问题。但是依然有两个问题没有解决:
- 海量数据存储问题
- 高并发写的问题
使用分片集群可以解决上述问题,分片集群特征:
- 集群中有多个 master,每个 master 保存不同数据
- 每个 master 都可以有多个 slave 节点
- master 之间通过 ping 监测彼此健康状态
- 客户端请求可以访问集群任意节点,最终都会被转发到正确节点
散列插槽
Redis 会把每一个 master 节点映射到 0~16383 共 16384 个插槽(hash slot)上,查看集群信息时就能看到:
1 | M: f5fc58defbebb957e47fb0d8327a09d4cf1678f5 192.168.150.101:7001 |
数据 key 不是与节点绑定,而是与插槽绑定。redis 会根据 key 的有效部分计算插槽值,分两种情况:
- key 中包含 “{}”,且 “{}” 中至少包含 1 个字符,“{}” 中的部分是有效部分
- key 中不包含 “{}”,整个 key 都是有效部分
例如:key 是 num,那么就根据 num 计算,如果是 {itcast} num,则根据 itcast 计算。计算方式是利用 CRC16 算法得到一个 hash 值,然后对 16384 取余,得到的结果就是 slot 值。
1 | 127.0.0.1:7001> set a 1 |
集群伸缩
核心是插槽(hash slot)的重新分配,因为数据与插槽绑定、插槽与节点绑定,所以伸缩本质是调整 “节点 - 插槽” 的映射关系,同时保证数据在节点间迁移时集群仍可用。
新增节点并加入集群
先启动新的 Redis 节点(配置为集群模式),通过
redis-cli --cluster add-node 新节点IP:端口 集群任意节点IP:端口将新节点加入集群(此时新节点无插槽,仅作为 “空节点” 存在)。插槽迁移规划
确定要从原有 master 节点迁移哪些插槽到新节点(比如从原有 3 个 master 的插槽区间中,拆分部分插槽给新节点)。Redis 集群的插槽总数固定为 16384,迁移时需保证每个插槽仅归属一个 master。
插槽迁移执行
触发迁移:通过
redis-cli --cluster reshard 集群任意节点IP:端口命令,交互式指定 “迁移的插槽总数”“目标节点 ID”“源节点 ID”,Redis 会自动计算待迁移的插槽列表。数据迁移:Redis 会先将待迁移插槽的
数据键
从源节点逐步迁移到目标节点,迁移过程中:
- 读请求:若键已迁移完成,路由到新节点;若未完成,路由到原节点。
- 写请求:同时更新原节点和新节点(保证数据一致性),迁移完成后取消原节点的写权限。
更新插槽映射:迁移完成后,集群会广播新的 “节点 - 插槽” 映射关系,所有节点和客户端更新本地缓存。
故障转移
分片集群中主节点宕机后,也会自动提升一个 slave 为新的 master
利用cluster failover命令可以手动让集群中的某个 master 宕机,切换到执行 cluster failover 命令的这个 slave 节点,实现无感知的数据迁移。其流程如下:
- slave 节点告诉 master 节点拒绝任何客户端请求
- master 返回当前的数据 offset 给 slave
- 等待数据 offset 与 master 一致
- 开始故障转移(slave 和 master 同时执行)
- slave 标记自己为 master,广播故障转移的结果
- 其它 master 收到广播,开始处理客户端读请求

多级缓存
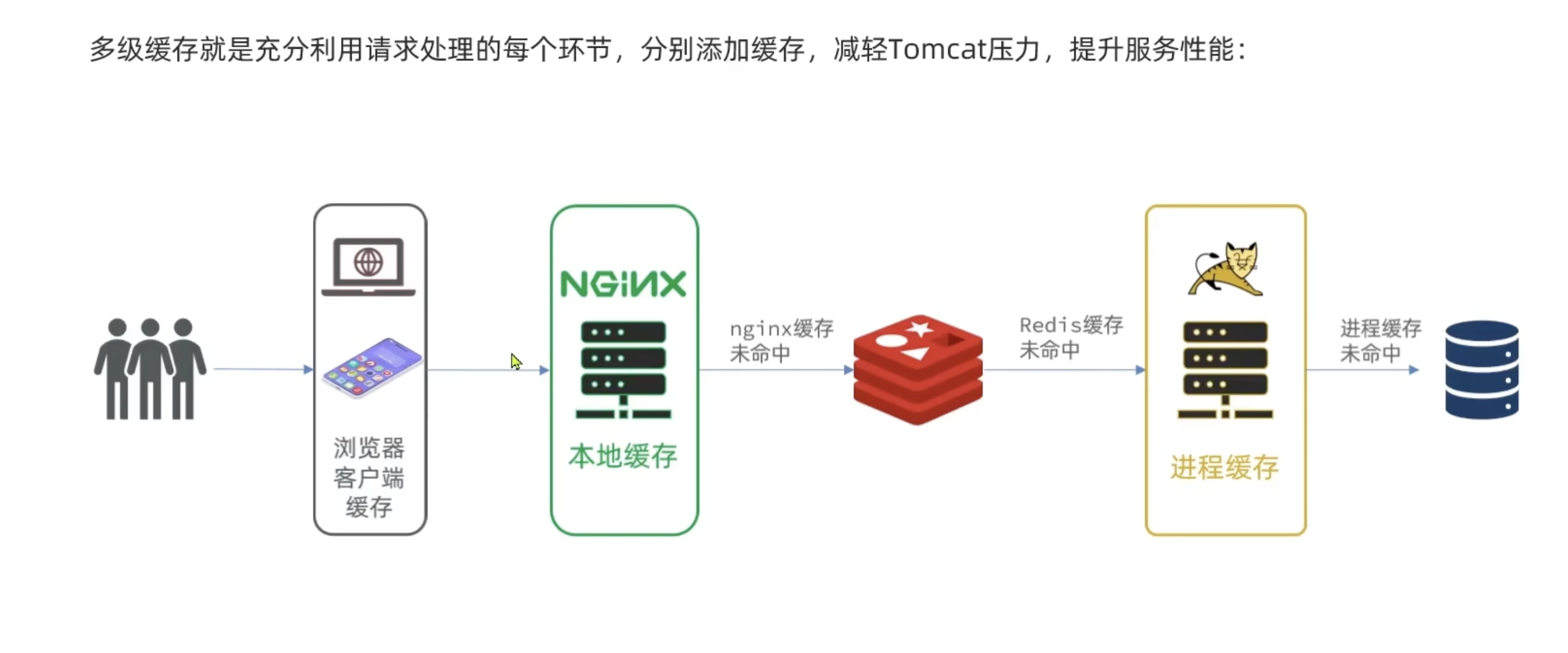
浏览器缓存->Nginx 缓存->Redis->进程缓存->数据库
数据库表设计逻辑:为了让缓存经常命中不打入数据库,要把经常修改的数据和不经常修改的数据分开,形成多张表。
exp:商品的库存经常修改,如果不分离商品信息全存一张表,一修改商品的库存,商品信息的缓存会一起失效。
JVM 进程缓存
缓存在日常开发中启动至关重要的作用,由于是存储在内存中,数据的读取速度是非常快的,能大量减少对数据库的访问,减少数据库的压力。我们把缓存分为两类:
- 分布式缓存,例如 Redis:
- 优点:存储容量更大、可靠性更好、可以在集群间共享
- 缺点:访问缓存有网络开销
- 场景:缓存数据量较大、可靠性要求较高、需要在集群间共享
- 进程本地缓存,例如 HashMap、GuavaCache:
- 优点:读取本地内存,没有网络开销,速度更快
- 缺点:存储容量有限、可靠性较低、无法共享
- 场景:性能要求较高,缓存数据量较小
Caffeine是一个基于Java8开发的,提供了近乎最佳命中率的高性能的本地缓存库。目前Spring内部的缓存使用的就是
GitHub地址:https://github.com/ben-manes/caffeine
示例代码:
1 |
|
Caffeine 提供了三种缓存驱逐策略:
基于容量:设置缓存的数量上限
1
2
3
4// 创建缓存对象
Cache<String, String> cache = Caffeine.newBuilder()
.maximumSize(1) // 设置缓存大小上限为 1
.build();基于时间:设置缓存的有效时间
1
2
3
4// 创建缓存对象
Cache<String, String> cache = Caffeine.newBuilder()
.expireAfterWrite(Duration.ofSeconds(10)) // 设置缓存有效期为 10 秒,从最后一次写入开始计时
.build();基于引用:设置缓存为软引用或弱引用,利用 GC 来回收缓存数据。性能较差,不建议使用。
在默认情况下,当一个缓存元素过期的时候,Caffeine 不会自动立即将其清理和驱逐。而是在一次读或写操作后,或者在空闲时间完成对失效数据的驱逐。
Redis 最佳实践
键值设计
优雅的 key 结构
Redis 的 Key 虽然可以自定义,但最好遵循下面的几个最佳实践约定:
- 遵循基本格式:
[业务名称]:[数据名]:[id] - 长度不超过 44 字节
- 不包含特殊字符
例如:登录业务,保存用户信息,其 key 是这样的:login:user:10
(对应结构:业务名称→login,数据名称→user,数据 id→10)
优点:
- 可读性强
- 避免 key 冲突
- 方便管理
- 更节省内存:key 是 string 类型,底层编码包含 int、embstr 和 raw 三种。embstr 在小于 44 字节使用,采用连续内存空间,内存占用更小
BigKey
BigKey 通常以 Key 的大小和 Key 中成员的数量来综合判定,例如:
- Key 本身的数据量过大:一个 String 类型的 Key,它的值为 5 MB。
- Key 中的成员数过多:一个 ZSET 类型的 Key,它的成员数量为 10,000 个。
- Key 中成员的数据量过大:一个 Hash 类型的 Key,它的成员数量虽然只有 1,000 个但这些成员的 Value(值)总大小为 100 MB。
推荐值:
- 单个 key 的 value 小于 10KB
- 对于集合类型的 key,建议元素数量小于 1000
BigKey的危害
网络阻塞:
- 对BigKey执行读请求时,少量的QPS就可能导致带宽使用率被占满,导致Redis实例,乃至所在物理机变慢
数据倾斜:
- Bigkey所在的Redis实例内存使用率远超其他实例,无法使数据分片的内存资源达到均衡
Redis阻塞:
- 对元素较多的hash、list、zset等做运算会耗时较久,使主线程被阻塞
CPU压力:
- 对BigKey的数据序列化和反序列化会导致CPU的使用率飙升,影响Redis实例和本机其它应用
发现BigKey
redis-cli –bigkeys
- 利用redis-cli提供的–bigkeys参数,可以遍历分析所有key,并返回Key的整体统计信息与每个数据的Top1的big key
scan扫描
- 自己编程,利用scan扫描Redis中的所有key,利用strlen、hlen等命令判断key的长度(此处不建议使用MEMORY USAGE)
第三方工具
- 利用第三方工具,如Redis-Rdb-Tools 分析RDB快照文件,全面分析内存使用情况
网络监控
- 自定义工具,监控进出Redis的网络数据,超出预警值时主动告警
删除 BigKey
BigKey 内存占用较多,即便是删除这样的 key 也需要耗费很长时间,导致 Redis 主线程阻塞,引发一系列问题。
redis 3.0 及以下版本
如果是集合类型,则遍历 BigKey 的元素,先逐个删除子元素,最后删除 BigKey
Redis 4.0 以后
Redis 在 4.0 后提供了异步删除的命令:
unlink
恰当的数据类型
例 1:比如存储一个 User 对象,我们有三种存储方式:
方式一:json 字符串
| key | value |
|---|---|
| user:1 | {“name”: “Jack”, “age”: 21} |
| 优点:实现简单粗暴 | |
| 缺点:数据耦合,不够灵活 |
方式二:字段打散
| key | value |
|---|---|
| user:1:name | Jack |
| user:1:age | 21 |
| 优点:可以灵活访问对象任意字段 | |
| 缺点:占用空间大、没办法做统一控制 |
方式三:hash
| key | 字段 | 值 |
|---|---|---|
| user:1 | name | Jack |
| age | 21 | |
| 优点:底层使用 ziplist,空间占用小,可以灵活访问对象的任意字段 | ||
| 缺点:代码相对复杂 |
例2:hash 类型的 key,有 100 万对 field 和 value,field 自增,优化这个 key
答:把大 Hash 拆成小 hash,将 id / 100 作为 key,id % 100 作为 field 和 value
| KEY | field | value |
|---|---|---|
| key:0 | id:00 | value0 |
| …… | …… | |
| id:99 | value99 | |
| key:1 | id:00 | value100 |
| …… | …… | |
| id:99 | value199 | |
| …… | …… | …… |
| key:9999 | id:00 | value999900 |
| …… | …… | |
| id:99 | value999999 |
总结
Key 的最佳实践:
- 固定格式:
[业务名]:[数据名]:[id] - 足够简短:不超过 44 字节
- 不包含特殊字符
Value 的最佳实践:
- 合理的拆分数据,拒绝 BigKey
- 选择合适数据结构
- Hash 结构的 entry 数量不要超过 1000
- 设置合理的超时时间
批处理
N 条命令依次执行
N 次命令的响应时间 = N 次往返的网络传输耗时 + N 次 Redis 执行命令耗时
执行流程:
- 客户端发送命令 1 → Redis 服务端执行命令 1 → 服务端返回结果 1;
- 客户端发送命令 2 → Redis 服务端执行命令 2 → 服务端返回结果 2;
- ……(重复上述步骤直到命令 N)
为什么网络传输耗时更大?
Redis 执行命令本身是内存级操作,速度极快(单条命令执行耗时通常在微秒级);
而网络传输需要经过「客户端→网络链路→服务端」的往返过程,涉及网络延迟、TCP 握手 / 数据包传输等开销,单次往返耗时通常在毫秒级(甚至更高,若网络环境差)。
N 条命令批量执行
N 次命令的响应时间 = 1 次往返的网络传输耗时 + N 次 Redis 执行命令耗时
执行流程:
- 客户端批量发送 N 条命令(仅 1 次网络请求);
- Redis 服务端执行这 N 个命令;
- 服务端批量返回 N 个结果(仅 1 次网络响应)。
MSET
Redis 提供了很多 Mxxx 这样的命令,可以实现批量插入数据,例如:
- mset
- hmset
不要在一次批处理中传太多命令,否则 占用带宽较多,造成网络阻塞
利用 mset 批量插入 10 万条数据:
1 |
|
Pipeline
MSET 虽然可以批处理,但是却只能操作部分数据类型,因此如果有对复杂数据类型的批处理需要,建议使用 Pipeline 功能:
1 |
|
但 Pipeline 的命令之间不具备原子性
集群下的批处理
如 MSET 或 Pipeline 这样的批处理需要在一次请求中携带多条命令,而此时如果 Redis 是一个集群,那批处理命令的多个 key 必须落在一个插槽中,否则就会导致执行失败。
| 串行命令 | 串行 slot | 并行 slot | hash_tag | |
|---|---|---|---|---|
| 实现思路 | for 循环遍历,依次执行每个命令 | 在客户端计算每个 key 的 slot,将 slot 一致分为一组,每组都利用 Pipeline 批处理。串行执行各组命令 | 在客户端计算每个 key 的 slot,将 slot 一致分为一组,每组都利用 Pipeline 批处理。并行执行各组命令 | 将所有 key 设置相同的 hash_tag,则所有 key 的 slot 一定相同 |
| 耗时 | N 次网络耗时 + N 次命令耗时 | m 次网络耗时 + N 次命令耗时m = key 的 slot 个数 | 1 次网络耗时 + N 次命令耗时 | 1 次网络耗时 + N 次命令耗时 |
| 优点 | 实现简单 | 耗时较短 | 耗时非常短 | 耗时非常短、实现简单 |
| 缺点 | 耗时非常久 | 实现稍复杂slot 越多,耗时越久 | 实现复杂 | 容易出现数据倾斜 |
SpringRedisTemplate.opsForValue().multiSet()就是并行 slot
持久化配置
Redis的持久化虽然可以保证数据安全,但也会带来很多额外的开销,因此持久化请遵循下列建议:
① 用来做缓存的Redis实例尽量不要开启持久化功能
② 建议关闭RDB持久化功能,使用AOF持久化或者使用混合策略
③ 利用脚本定期在slave节点做RDB,实现数据备份
④ 设置合理的rewrite阈值,避免频繁的bgrewrite(AOF 文件重写)
⑤ 配置no-appendfsync-on-rewrite = yes,禁止在rewrite期间做aof,避免因AOF引起的阻塞
在
bgrewriteaof(AOF 文件重写)过程中,暂时禁止 Redis 主进程执行fsync()系统调用去刷写 AOF 缓冲区数据到磁盘,仅将 AOF 命令写入内存缓冲区即可,以此避免主进程阻塞。
部署有关建议:
- ① Redis实例的物理机要预留足够内存,应对fork和rewrite
- ② 单个Redis实例内存上限不要太大,例如4G或8G。可以加快fork的速度、减少主从同步、数据迁移压力
- ③ 不要与CPU密集型应用部署在一起
- ④ 不要与高硬盘负载应用一起部署。例如:数据库、消息队列
慢查询
慢查询的阈值可以通过配置指定:
slowlog-log-slower-than:慢查询阈值,单位是微秒。默认是 10000,建议 1000
慢查询会被放入慢查询日志中,日志的长度有上限,可以通过配置指定:
slowlog-max-len:慢查询日志(本质是一个队列)的长度。默认是 128,建议 1000
示例(查看当前配置):
1 | 127.0.0.1:6379> config get slowlog-max-len |
修改这两个配置可以使用:config set命令:
1 | 127.0.0.1:6379> config set slowlog-log-slower-than 1000 |
查看慢查询日志列表:
slowlog len:查询慢查询日志长度slowlog get [n]:读取 n 条慢查询日志slowlog reset:清空慢查询列表
示例(SLOWLOG get 1 输出解析):
1 | 127.0.0.1:6379> SLOWLOG get 1 |
命令及安全配置
风险背景
Redis 默认会绑定在0.0.0.0:6379,这会将服务暴露到公网;若未做身份认证,会出现严重安全漏洞。
漏洞重现方式:https://cloud.tencent.com/developer/article/1039000
安全配置建议
为避免漏洞,建议执行以下措施:
- Redis 一定要设置密码
(避免未授权访问,对应前文 “身份认证缺失风险”)
- 禁止线上使用高危命令:
如keys、flushall、flushdb、config set等,可通过rename-command配置禁用。
(keys命令是慢查询常见来源,前文 “慢查询” 中已说明其耗时风险)
- bind配置限制网卡:
禁止外网网卡访问,仅绑定内网 IP(避免公网暴露)。
- 开启防火墙:
限制仅信任 IP 能访问 Redis 端口。
- 不要使用 Root 账户启动 Redis:
降低权限泄露后的危害范围。
- 尽量不使用默认端口:
避免被扫描工具批量探测(默认 6379 易成为攻击目标)。
内存配置
当 Redis 内存不足时,可能导致 Key 频繁被删除、响应时间变长、QPS 不稳定等问题。当内存使用率达到 90% 以上时就需要我们警惕,并快速定位到内存占用的原因。
| 内存占用 | 说明 |
|---|---|
| 数据内存 | 是 Redis 最主要的部分,存储 Redis 的键值信息。主要问题是 BigKey 问题、内存碎片问题(释放 Redis 后被回收) |
| 进程内存 | Redis 主进程本身运行肯定需要占用内存,如代码、常量池等等;这部分内存大约几兆,在大多数生产环境中与 Redis 数据占用的内存相比可以忽略。 |
| 缓冲区内存 | 一般包括客户端缓冲区、AOF 缓冲区、复制缓冲区等。客户端缓冲区又包括输入缓冲区和输出缓冲区两种。这部分内存占用波动较大,不当使用 BigKey,可能导致内存溢出。 |
集群配置
集群完整性问题
在 Redis 的默认配置中,如果发现任意一个插槽不可用,则整个集群都会停止对外服务:
为了保证高可用特性,建议将cluster-require-full-coverage配置为no
集群带宽问题
集群节点之间会不断的互相 Ping 来确定集群中其它节点的状态。每次 Ping 携带的信息至少包括:
- 插槽信息
- 集群状态信息
集群中节点越多,集群状态信息数据量也越大,10 个节点的相关信息可能达到 1kb,此时每次集群互通需要的带宽会非常高。
解决途径:
- 避免大集群,集群节点数不要太多,最好少于 1000,如果业务庞大,则建立多个集群。
- 避免在单个物理机中运行太多 Redis 实例
- 配置合适的 cluster-node-timeout 值
还有其他问题:数据倾斜、客户端性能、命令的集群兼容性、lua 和事务
深入 Redis 源码
Redis 数据结构
动态字符串 SDS
Redis 字符串数据结构对应的是 C 语言自定义的一个结构体:
1 | struct __attribute__((__packed__)) sdshdr8 { |
SDS 之所以叫做动态字符串,是因为它具备动态扩容的能力,例如一个内容为 “hi” 的 SDS:
1 | | len:2 | alloc:2 | flags:1 | h | i | \0 | |
假如我们要给 SDS 追加一段字符串 “,Amy”,这里首先会申请新内存空间:
- 如果新字符串小于 1M,则新空间为扩展后字符串长度的两倍 + 1;
- 如果新字符串大于 1M,则新空间为扩展后字符串长度 + 1M+1。称为内存预分配。
扩展后的 SDS:
1 | | len:6 | alloc:12 | flags:1 | h | i | , | A | m | y | \0 | (剩余空闲空间) | |
优点
- 获取字符串长度的时间复杂度为 O (1)
- 支持动态扩容
- 减少内存分配次数
- 二进制安全
IntSet
IntSet 是 Redis 中 set 集合的一种实现方式,基于整数数组来实现,并且具备长度可变、有序等特征。
结构如下:
1 | typedef struct intset { |
其中的 encoding 包含三种模式,表示存储的整数大小不同:
1 | /* Note that these encodings are ordered, so: |
为了方便查找,Redis 会将 intset 中所有的整数按照升序依次保存在 contents 数组中,结构如图:
1 | +---------------------------+---------+----+----+----+ |
现在,数组中每个数字都在 int16_t 的范围内,因此采用的编码方式是 INTSET_ENC_INT16,每部分占用的字节大小为:
- encoding:4 字节
- length:4 字节
- contents:2 字节 * 3 = 6 字节
数据地址的寻址方式:start + (sizeof(int16) * index)
IntSet 升级
现在,假设有一个 intset,元素为 {5,10, 20},采用的编码是 INTSET_ENC_INT16,则每个整数占 2 字节:
1 | +----+----+----+--------+ |
我们向该其中添加一个数字:50000,这个数字超出了 int16_t 的范围,intset 会自动升级编码方式到合适的大小。
以当前案例来说流程如下:
① 升级编码为 INTSET_ENC_INT32,每个整数占 4 字节,并按照新的编码方式及元素个数扩容数组
② 倒序依次将数组中的元素拷贝到扩容后的正确位置
③ 将待添加的元素放入数组末尾
Intset可以看做是特殊的整数数组,具备一些特点:
- ① Redis会确保Intset中的元素唯一、有序
- ② 具备类型升级机制,可以节省内存空间
- ③ 底层采用二分查找方式来查询
Dict
我们知道 Redis 是一个键值型(Key-Value Pair)的数据库,我们可以根据键实现快速的增删改查。而键与值的映射关系正是通过 Dict 来实现的。
Dict 由三部分组成,分别是:哈希表(DictHashTable)、哈希节点(DictEntry)、字典(Dict)
哈希表(dictht)结构定义:
1 | typedef struct dictht { |
哈希节点(dictEntry)结构定义:
1 | typedef struct dictEntry { |
used 为什么可能比size 大??
在 Redis 的dictht(哈希表)中,used代表哈希表中已存储的dictEntry节点数量,size代表哈希表数组(table)的长度。
正常情况下used应该≤size,但used比size大的场景,是因为哈希表采用了 “拉链法” 解决哈希冲突:
当多个dictEntry的哈希值映射到数组的同一个下标时,这些节点会通过next指针连成链表,此时一个数组下标可以挂多个dictEntry。
举个例子:
- 若
size=4(数组长度为 4),但有 6 个dictEntry通过哈希冲突挂在不同数组下标对应的链表上,此时used=6、size=4,used就会大于size。
本质是:size是数组的容量,used是实际存储的节点总数,拉链法允许一个数组位置挂多个节点,所以used可以超过size。
当我们向Dict添加键值对时,Redis首先根据key计算出hash值(h),然后利用h&sizemask来计算元素应该存储到数组中的哪个索引位置。
为什么不用 %(取模) 而用 & (按位与)运算?
1. 核心前提:哈希表的 size 必须是 2 的幂次
Redis 会强制让哈希表的size(数组长度)始终是 2 的整数次幂(比如 2、4、8、16、32…),此时size - 1的二进制形式是 “全 1” 的:
- 示例:size=8(2³)→ size-1=7 → 二进制
0111 - 示例:size=16(2⁴)→ size-1=15 → 二进制
1111
这个size-1就是哈希表中的sizemask字段,是实现&运算的关键。
2. 按位与 (&) 和取模 (%) 的等价性
当除数(这里是size)是 2 的幂次时,一个数对 size 取模的结果 = 这个数 & (size - 1),举个直观例子:
假设哈希值hash=19,size=8(2³):
取模计算:19 % 8 = 3
按位与计算:
19 的二进制是
10011,size-1=7 的二进制是00111两者按位与:1
2
3
410011
& 00111
------
00011 → 十进制3
结果完全一致。
运算效率天差地别:
计算机硬件对二进制位运算(&、|、^ 等)的支持是 “原生级” 的,CPU 只需 1 个时钟周期就能完成;而取模运算(%)本质是除法运算的衍生,需要多个时钟周期,且编译器难以优化。
对于 Redis 这种追求极致性能的中间件,每一次哈希计算的微小耗时,在高并发场景下都会被无限放大,位运算能显著降低 CPU 开销。
ps:面试题:为什么 HashMap 扩容时容量乘 2
- 哈希表容量
capacity必须是2 的整数次幂(初始容量 16=2⁴,扩容后 32=2⁵,以此类推); - 此时
capacity-1的二进制是 “全 1” 形式(比如 16-1=15→1111); - 计算元素下标时,用
(hash & (capacity-1))代替(hash % capacity),按位与运算的效率远高于取模,这是 HashMap 高性能的关键优化。
- 哈希表容量
总结Redis 计算元素位置的实际步骤:
- 对 key 做哈希运算,得到 64 位的哈希值
hash; - 用
hash & dictht.sizemask(即hash & (size-1))计算出数组下标; - 将 dictEntry 节点放入该下标对应的位置(有冲突则挂到链表后)。
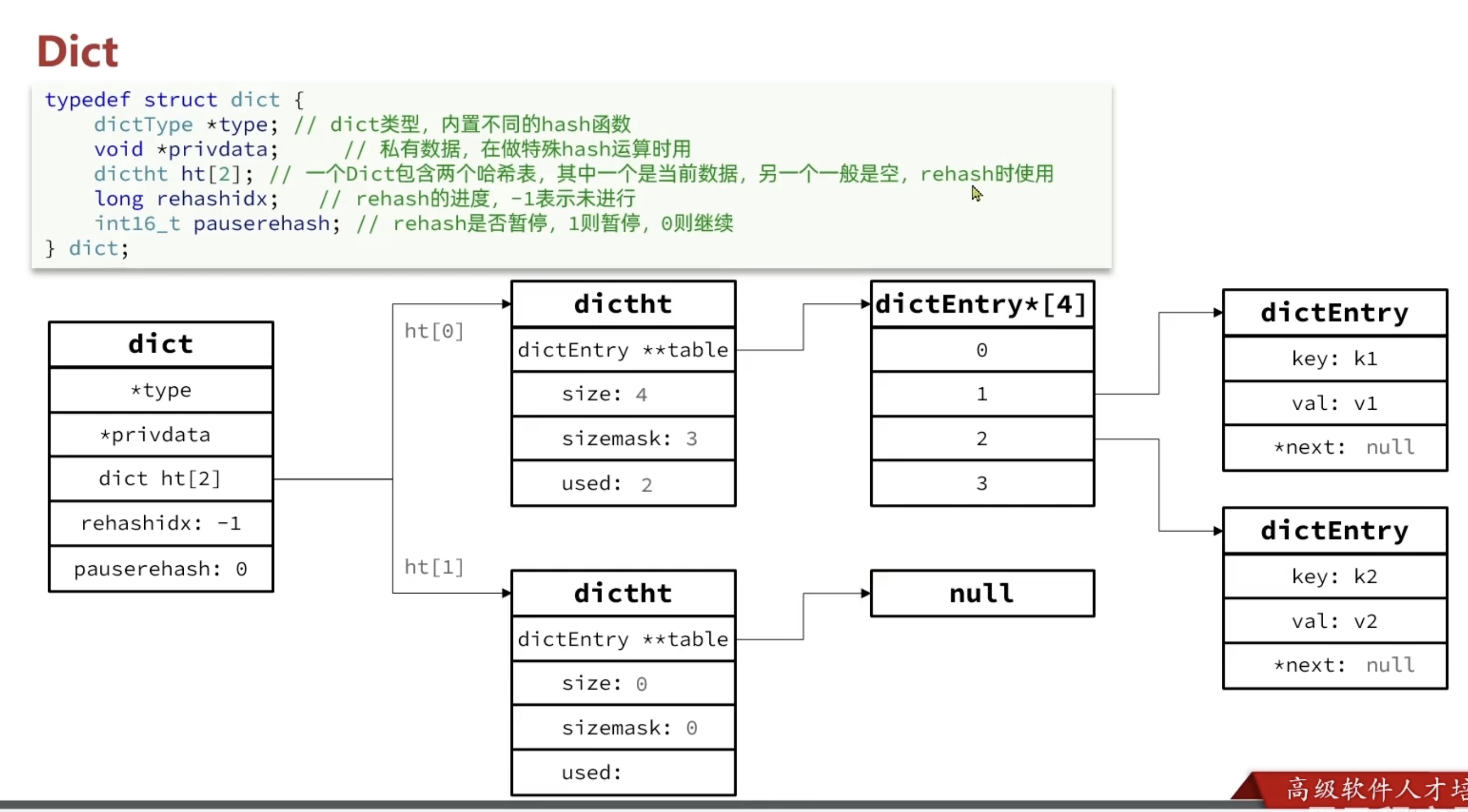
Dict 结构体
1 | typedef struct dict { |
Dict 的扩容
Dict 中的 HashTable 是数组结合单向链表的实现,当集合中元素较多时,必然导致哈希冲突增多,链表过长,则查询效率会大大降低。
Dict 在每次新增键值对时都会检查负载因子(LoadFactor = used/size),满足以下两种情况时会触发哈希表扩容:
- 哈希表的
LoadFactor >= 1,并且服务器没有执行BGSAVE或者BGREWRITEAOF等后台进程; - 哈希表的
LoadFactor > 5;
LoadFactor是哈希表中 “已用节点数” 与 “哈希表容量” 的比值,用于衡量哈希表的 “拥挤程度”,负载因子越高,说明哈希表越 “拥挤”,哈希冲突的概率越大(链表会越长),查询 / 插入的效率会下降;负载因子越低,哈希表越 “宽松”,冲突越少,但内存利用率会降低。
对应的核心代码(_dictExpandIfNeeded函数):
1 | static int _dictExpandIfNeeded(dict *d){ |
Dict 的 rehash
Dict 的 rehash 并不是一次性完成的。试想一下,如果 Dict 中包含数百万的 entry,要在一次 rehash 完成,极有可能导致主线程阻塞。因此 Dict 的 rehash 是分多次、渐进式的完成,因此称为渐进式 rehash。流程如下:
① 计算新 hash 表的 size,取值取决于当前要做的是扩容还是收缩:
- 如果是扩容,则新 size 为第一个大于等于
dict.ht[0].used + 1的 2ⁿ - 如果是收缩,则新 size 为第一个大于等于
dict.ht[0].used的 2ⁿ(不得小于 4)
② 按照新的 size 申请内存空间,创建 dictht,并赋值给dict.ht[1]
③ 设置dict.rehashidx = 0,标示开始 rehash
④ 每次执行新增、查询、修改、删除操作时,都检查一下dict.rehashidx是否大于 - 1,如果是则将dict.ht[0].table[rehashidx]的 entry 链表 rehash 到dict.ht[1],并且将rehashidx++。直至dict.ht[0]的所有数据都 rehash 到dict.ht[1]
⑤ 将dict.ht[1]赋值给dict.ht[0],给dict.ht[1]初始化为空哈希表,释放原来的dict.ht[0]的内存
⑥ 将rehashidx赋值为 - 1,代表 rehash 结束
⑦ 在 rehash 过程中,新增操作,则直接写入 ht [1],查询、修改和删除则会在dict.ht[0]和dict.ht[1]依次查找并执行。这样可以确保 ht [0] 的数据只减不增,随着 rehash 最终为空
ZipList
ZipList 是一种特殊的 “双端链表”,由一系列特殊编码的连续内存块组成。可以在任意一端进行压入 / 弹出操作,并且该操作的时间复杂度为 O (1)。
ZipList 是 Redis 中 List 列表、Hash 哈希、Sorted Set 有序集合的底层实现之一,仅用于存储 “小数据量、小元素” 场景,以节省内存。
其结构组成:
1 | +--------+--------+--------+-------+-------+-------+-------+--------+ |
各属性的详细信息:
| 属性 | 类型 | 长度 | 用途 |
|---|---|---|---|
| zbytes | uint32_t | 4 字节 | 记录整个压缩列表占用的内存字节数 |
| zltail | uint32_t | 4 字节 | 记录压缩列表尾节点距离压缩列表起始地址的字节偏移量,用于快速定位尾节点地址 |
| zllen | uint16_t | 2 字节 | 记录压缩列表的节点数量,最大值为 65534;超过则记为 65535,需遍历列表获取真实数量 |
| entry | 列表节点 | 不定 | 压缩列表的存储节点,节点长度由其保存的内容决定 |
| zlend | uint8_t | 1 字节 | 特殊值 0xFF(十进制 255),用于标记压缩列表的末端 |
ZipListEntry
ZipList 中的 Entry 并不像普通链表那样记录前后节点的指针,因为记录两个指针要占用 16 个字节,浪费内存。而是采用了下面的结构:
1 | +-----------------------+----------+---------+ |
- previous_entry_length:前一节点的长度,占 1 个或 5 个字节。
- 如果前一节点的长度小于 254 字节,则采用 1 个字节来保存这个长度值
- 如果前一节点的长度大于 254 字节,则采用 5 个字节来保存这个长度值,第一个字节为 0xfe,后四个字节才是真实长度数据
- encoding:编码属性,记录 content 的数据类型(字符串还是整数)以及长度,占用 1 个、2 个或 5 个字节
- contents:负责保存节点的数据,可以是字符串或整数
注意
ZipList 中所有存储长度的数值均采用小端字节序,即低位字节在前,高位字节在后。例如:
数值 0x1234,采用小端字节序后实际存储值为:0x3412。小端存储是为了方便计算机运算
Encoding 编码
ZipListEntry 中的 encoding 编码分为字符串和整数两种:
- 字符串:如果 encoding 是以 “00”、“01” 或者 “10” 开头,则证明 content 是字符串
| 编码 | 编码长度 | 字符串大小 |
|---|---|---|
| |00pppppp| | 1 bytes | <= 63 bytes |
| |01pppppp|qqqqqqqq| | 2 bytes | <= 16383 bytes |
| |10000000|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| | 5 bytes | <= 4294967295 bytes |
例如,我们要保存字符串:“ab” 和 “bc”
对应的 ZipList 结构(各部分长度标注):
| 字节偏移(十进制) | 字段归属 | 具体字段 / 子字段 | 占用字节 | 十六进制值(小端) | 十进制值 | 核心含义说明 |
|---|---|---|---|---|---|---|
| 0-3 | ZipList 头部 | zbytes | 4 | 0x13 0x00 0x00 0x00 | 19 | 整个 ZipList 总字节数(4+4+2+4+4+1=19) |
| 4-7 | ZipList 头部 | zltail | 4 | 0x0e 0x00 0x00 0x00 | 14 | 尾节点(“bc”)距离起始地址的偏移量:从第 14 字节开始是 “bc” 节点 |
| 8-9 | ZipList 头部 | zllen | 2 | 0x02 0x00 | 2 | Entry 节点总数(“ab” 和 “bc” 共 2 个) |
| 10 | entry1(ab) | previous_entry_length | 1 | 0x00 | 0 | 前一个节点长度(第一个节点无前驱,记为 0) |
| 11 | entry1(ab) | encoding | 1 | 0x02 | 2 | 字符串编码(00000010):00 开头,字符串长度为 2 字节 |
| 12-13 | entry1(ab) | content | 2 | 0x61 0x62 | - | 字符串 “ab”(0x61=‘a’,0x62=‘b’) |
| 14 | entry2(bc) | previous_entry_length | 1 | 0x04 | 4 | 前一个节点(ab)总长度:1(prev)+1(encoding)+2(content)=4 |
| 15 | entry2(bc) | encoding | 1 | 0x02 | 2 | 字符串编码(00000010):00 开头,字符串长度为 2 字节 |
| 16-17 | entry2(bc) | content | 2 | 0x62 0x63 | - | 字符串 “bc”(0x62=‘b’,0x63=‘c’) |
| 18 | ZipList 尾部 | zlend | 1 | 0xFF | 255 | ZipList 结束标记(固定值) |
- 整数:如果 encoding 是以 “11” 开始,则证明 content 是整数,且 encoding 固定只占用 1 个字节
| 编码 | 编码长度 | 整数类型 |
|---|---|---|
| 11000000 | 1 | int16_t(2 bytes) |
| 11010000 | 1 | int32_t(4 bytes) |
| 11100000 | 1 | int64_t(8 bytes) |
| 11110000 | 1 | 24 位有符整数(3 bytes) |
| 11111110 | 1 | 8 位有符整数(1 bytes) |
| 1111xxxx | 1 | 直接在 xxxx 位置存数值,范围 0001~1101,减 1 后为实际值 |
示例(存储整数 “2” 和 “5” 的 ZipList 结构)
| 字段名 | 占用字节 | 内容(十六进制) | 说明 |
|---|---|---|---|
| zbytes | 4 | 0x0f000000 | 总字节数:15 |
| zltail | 4 | 0x0c000000 | 尾偏移量:12 |
| zllen | 2 | 0x0200 | 节点数:2 |
| entry1 | 2 | 0x00 0xf3 | 前节点长度(0)+ encoding(0xf3=11110011,对应 1111xxxx,数值 3-1=2) |
| entry2 | 2 | 0x02 0xf6 | 前节点长度(2)+ encoding(0xf6=11110110,对应 1111xxxx,数值 6-1=5) |
| zlend | 1 | 0xff | 结束标记 |
ZipList 的连锁更新问题
ZipList 的每个 Entry 都包含previous_entry_length来记录上一个节点的大小,长度是 1 个或 5 个字节:
- 如果前一节点的长度小于 254 字节,则采用 1 个字节来保存这个长度值
- 如果前一节点的长度大于等于 254 字节,则采用 5 个字节来保存这个长度值,第一个字节为 0xfe,后四个字节才是真实长度数据
现在,假设我们有 N 个连续的、长度为 250~253 字节之间的 entry,因此 entry 的previous_entry_length属性用 1 个字节即可表示,结构如下:
1 | +--------+--------+--------+------------+------------+--------+------------+--------+ |
ZipList 这种特殊情况下产生的连续多次空间扩展操作称之为连锁更新(Cascade Update)。新增、删除都可能导致连锁更新的发生。重新申请分配内存要从用户态切到内核态,影响性能,不过发生这种情况的概率极低。
ZipList特性:
- ① 压缩列表是可以看做一种连续内存空间的”双向链表”
- ② 列表的节点之间不是通过指针连接,而是记录上一节点和本节点长度来寻址,内存占用较低
- ③ 如果列表数据过多,导致链表过长,可能影响查询性能
- ④ 增或删较大数据时有可能发生连续更新问题
QuickList

针对 ZipList 的问题,Redis 3.2 版本引入了 QuickList,核心是 “双端链表 + ZipList 分片” 的组合结构,解决思路如下:
问题 1:ZipList 需连续内存,大内存申请效率低
✅ 限制 ZipList 的长度和 entry 大小,避免单个 ZipList 占用过多连续内存。
问题 2:数据量超出 ZipList 上限
✅ 用多个 ZipList 分片存储数据,每个 ZipList 存储部分数据。
问题 3:多 ZipList 分散,不便管理
✅ QuickList 是一个双端链表,链表的每个节点(QuickList Node)都是一个独立的 ZipList,通过链表节点的前后指针关联所有 ZipList 分片。
QuickList 结构示意图
1 | head ←→ QuickList Node ←→ QuickList Node ←→ ... ←→ QuickList Node ←→ tail |
QuickList 的list-compress-depth配置
除了控制 ZipList 的大小,QuickList 还可以对节点的 ZipList 做压缩。通过配置项list-compress-depth来控制。因为链表一般都是从首尾访问较多,所以首尾是不压缩的。这个参数是控制首尾不压缩的节点个数:
0:特殊值,代表不压缩1:标示 QuickList 的首尾各有 1 个节点不压缩,中间节点压缩2:标示 QuickList 的首尾各有 2 个节点不压缩,中间节点压缩- 以此类推
其默认值为0,可通过命令查看:
1 | 127.0.0.1:6379> config get list-compress-depth |
为什么需要压缩?
QuickList 的每个节点是 ZipList,即使分片存储,当数据量很大时,中间节点的访问频率较低(链表通常首尾操作多),这些节点占用的内存仍会造成浪费。压缩中间节点可以大幅减少内存占用,同时不影响首尾节点的访问效率。
怎么压缩的?
Redis 使用LZF 压缩算法对 QuickList 的中间 ZipList 节点进行压缩:
- 当
list-compress-depth设为非 0 值时,QuickList 会对 “首尾不保护” 的中间节点执行 LZF 压缩; - 压缩后,ZipList 的原始数据会被替换为 “压缩后的字节流 + 压缩标识”;
- 当需要访问压缩节点时,Redis 会先解压缩,再读取数据(因中间节点访问少,解压缩的性能开销可接受)。
ps:LZF 是一种 轻量级无损数据压缩算法,核心特点是 快速压缩/解压、低内存占用,主打“速度优先于压缩比”,适用于对性能敏感、无需极致压缩率的场景(如内存数据缓存、实时传输等)。
以下是 QuickList 和 QuickListNode 的结构源码:
QuickList 结构
1 | typedef struct quicklist { |
QuickListNode 结构
1 | typedef struct quicklistNode { |

总结QuickList的特点:
- 是一个节点为ZipList的双端链表
- 节点采用ZipList,解决了传统链表的内存占用问题
- 控制了ZipList大小,解决连续内存空间申请效率问题
- 中间节点可以压缩,进一步节省了内存
SkipList
SkipList(跳表)首先是链表,但与传统链表相比有几点差异:
- 元素按照升序排列存储
- 节点可能包含多个指针,指针跨度不同。
对应的结构示意图:
1 | 四级指针: 1 ---------------------------> 10 |
以下是 SkipList 的源码结构(来自t_zset.c):
zskiplist 结构
1 | typedef struct zskiplist { |
zskiplistNode 结构
1 | typedef struct zskiplistNode { |
结构图:
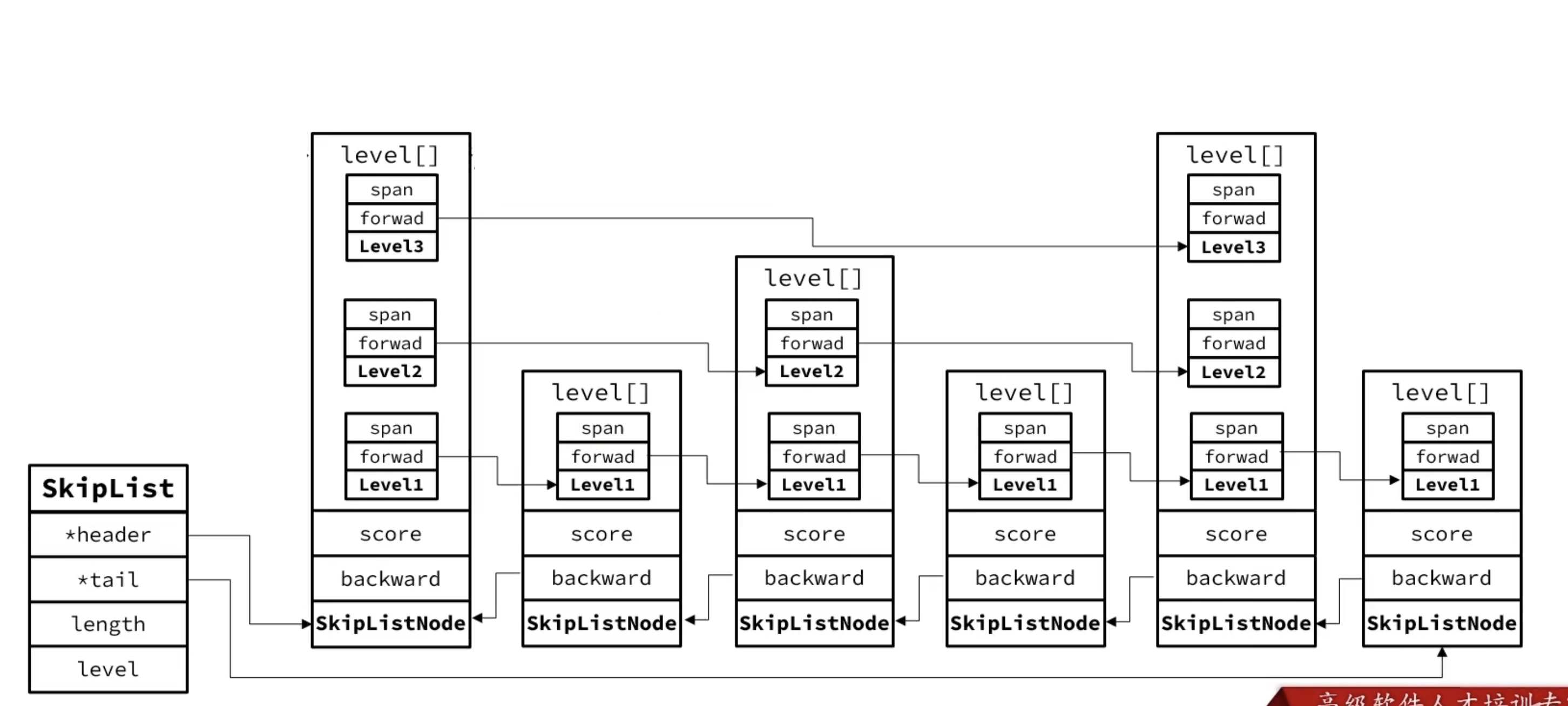
RedisObject
Redis 中的任意数据类型的键和值都会被封装为一个 RedisObject,也叫做 Redis 对象,源码如下:
1 | // 对象类型定义 |
Redis 的编码方式
Redis 中会根据存储的数据类型不同,选择不同的编码方式,共包含 11 种不同类型:
| 编号 | 编码方式 | 说明 |
|---|---|---|
| 0 | OBJ_ENCODING_RAW | raw 编码动态字符串 |
| 1 | OBJ_ENCODING_INT | long 类型的整数的字符串 |
| 2 | OBJ_ENCODING_HT | 哈希表(字典 dict) |
| 3 | OBJ_ENCODING_ZIPMAP | 已废弃 |
| 4 | OBJ_ENCODING_LINKEDLIST | 双端链表 |
| 5 | OBJ_ENCODING_ZIPLIST | 压缩列表 |
| 6 | OBJ_ENCODING_INTSET | 整数集合 |
| 7 | OBJ_ENCODING_SKIPLIST | 跳表 |
| 8 | OBJ_ENCODING_EMBSTR | embstr 的动态字符串 |
| 9 | OBJ_ENCODING_QUICKLIST | 快速列表 |
| 10 | OBJ_ENCODING_STREAM | Stream 流 |
Redis 中会根据存储的数据类型不同,选择不同的编码方式。每种数据类型的使用的编码方式如下:
| 数据类型 | 编码方式 |
|---|---|
| OBJ_STRING | int、embstr、raw |
| OBJ_LIST | LinkedList 和 ZipList(3.2 以前)、QuickList(3.2 以后) |
| OBJ_SET | intset、HT |
| OBJ_ZSET | ZipList、HT、SkipList |
| OBJ_HASH | ZipList、HT |
数据类型
String
String是Redis中最常见的数据存储类型:
- 其基本编码方式是RAW,基于简单动态字符串(SDS)实现,存储上限为512mb。
- 如果存储的SDS长度小于44字节,则会采用EMBSTR编码,此时object head与SDS是一段连续空间。申请内存时只需要调用一次内存分配函数,效率更高。
- 如果存储的字符串是整数值,并且大小在LONG_MAX范围内,则会采用INT编码:直接将数据保存在RedisObject的ptr指针位置(刚好8字节),不再需要SDS了。
结构图:

List
Redis 的 List 结构实现说明
Redis 的 List 结构类似一个双端链表,可以从首、尾操作列表中的元素:
- 在 3.2 版本之前,Redis 采用 ZipList 和 LinkedList 来实现 List,当元素数量小于 512 并且元素大小小于 64 字节时采用 ZipList 编码,超过则采用 LinkedList 编码。
- 在 3.2 版本之后,Redis 统一采用 QuickList 来实现 List。
对应的核心代码片段:
1. pushGenericCommand(List 操作的通用命令逻辑)
1 | void pushGenericCommand(client *c, int where, int xx) { |
2. createQuicklistObject(创建 QuickList 对象)
1 | robj *createQuicklistObject(void) { |
Set
Set是Redis中的单列集合,满足下列特点:
• 不保证有序性
• 保证元素唯一(可以判断元素是否存在)
• 求交集、并集、差集
可以看出,Set对查询元素的效率要求非常高,思考一下,什么样的数据结构可以满足?
• HashTable,也就是Redis中的Dict,不过Dict是双列集合(可以存键、值对)
Set 是 Redis 中的集合,不一定确保元素有序,可以满足元素唯一、查询效率要求极高。
- 为了查询效率和唯一性,set 采用 HT 编码(Dict)。Dict 中的 key 用来存储元素,value 统一为 null。
- 当存储的所有数据都是整数,并且元素数量不超过
set-max-intset-entries时,Set 会采用 IntSet 编码,以节省内存。
核心代码片段
1. setTypeCreate(创建 Set 对象,选择编码方式)
1 | robj *setTypeCreate(sds value) { |
2. createIntsetObject(创建 IntSet 编码的 Set 对象)
1 | robj *createIntsetObject(void) { |
3. createSetObject(创建 HT 编码的 Set 对象)
1 | robj *createSetObject(void) { |
配置说明
set-max-intset-entries的默认值是 512,可通过命令查看:
1 | 127.0.0.1:6379> config get set-max-intset-entries |

ZSet(SortedSet)
ZSet 也就是 SortedSet,其中每一个元素都需要指定一个 score 值和 member 值:
- 可以根据 score 值排序
- member 必须唯一
- 可以根据 member 查询分数
因此,zset 底层数据结构必须满足键值存储、键必须唯一、可排序这几个需求,通过以下编码结构组合实现:
- SkipList:可以排序,并且可以同时存储 score 和 ele 值(member)
- HT(Dict):可以键值存储,并且可以根据 key 找 value
核心结构与代码
1. zset 结构
1 | typedef struct zset { |
2. createZsetObject(创建 ZSet 对象)
1 | robj *createZsetObject(void) { |
示例操作
1 | 127.0.0.1:6379> ZADD z1 10 m1 20 m2 30 m3 |
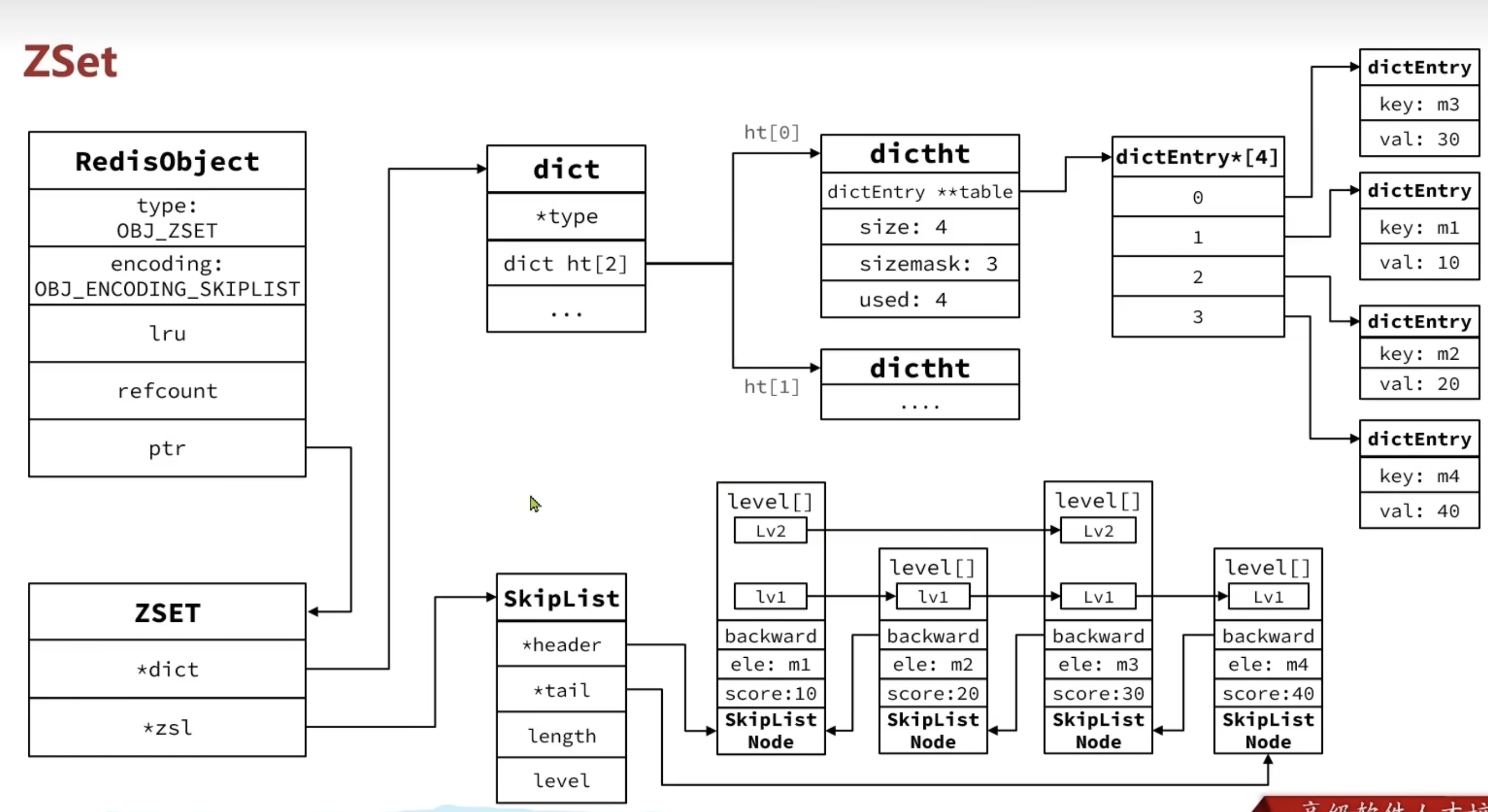
当元素数量不多时,HT和SkipList的优势不明显,而且更耗内存。因此zset还会采用ZipList结构来节省内存,不过需要同时满足两个条件:
- ① 元素数量小于zset_max_ziplist_entries,默认值128
- ② 每个元素都小于zset_max_ziplist_ value字节,默认值64
ziplist本身没有排序功能,而且没有键值对的概念,因此需要有zset通过编码实现:
- zipList是连续内存,因此score和element是紧挨在一起的两个entry,element在前,score在后
- score越小越接近队首,score越大越接近队尾,按照score值升序排列
Hash
Hash 结构与 ZSet 的对比
Hash 结构与 Redis 中的 Zset 非常类似:
- 都是键值存储
- 都需求根据键获取值
- 键必须唯一
区别如下:
- zset 的键是 member,值是 score;hash 的键和值都是任意值
- zset 要根据 score 排序;hash 则无需排序
因此,Hash 底层采用的编码与 Zset 也基本一致,只需要把排序有关的 SkipList 去掉即可。
- Hash 结构默认采用 ZipList 编码,用以节省内存。ZipList 中相邻的两个 entry 分别保存 field 和 value
- 当数据量较大时,Hash 结构会转为 HT 编码,也就是 Dict,触发条件有两个:
- ZipList 中的元素数量超过了
hash-max-ziplist-entries(默认 512) - ZipList 中的任意 entry 大小超过了
hash-max-ziplist-value(默认 64 字节)
- ZipList 中的元素数量超过了
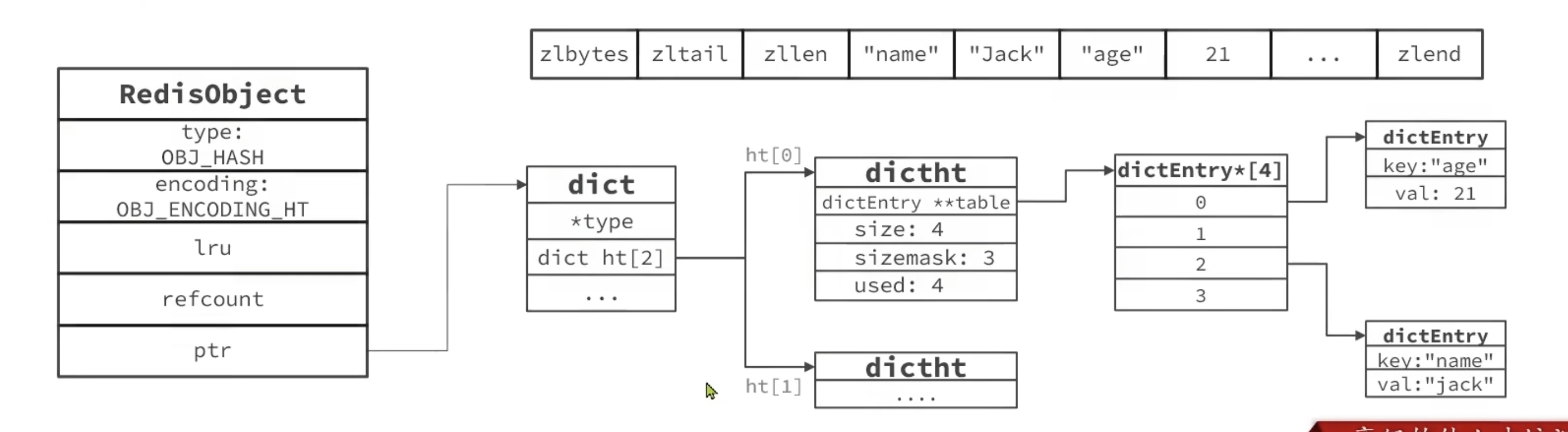
Hash 结构的相关代码
hsetCommand(HSET 命令的核心逻辑)
1 | void hsetCommand(client *c) { // hset user1 name Jack age 21 |
hashTypeLookupWriteOrCreate(查找或创建 Hash 对象)
1 | robj *hashTypeLookupWriteOrCreate(client *c, robj *key) { |
createHashObject(创建 Hash 对象,默认 ZipList 编码)
1 | robj *createHashObject(void) { |
- 根据
ziplist大小判断是否要把ZipList转换为Dict
1 | void hashTypeTryConversion(robj *o, robj **argv, int start, int end) { |
- 插入元素(在这里判断元素的数量是否超过
hash-max-ziplist-entries,超过就转换为Dict)
1 | int hashTypeSet(robj *o, sds field, sds value, int flags) { |
Redis 网络模型
Linux 的五种 IO 模型
在《UNIX网络编程》一书中,总结归纳了5种10模型:
• 阻塞IO(Blocking IO)
• 非阻塞IO(Nonblocking IO)
• IO多路复用 (IO Multiplexing)
• 信号驱动IO(Signal Driven IO)
• 异步IO(Asynchronous IO)
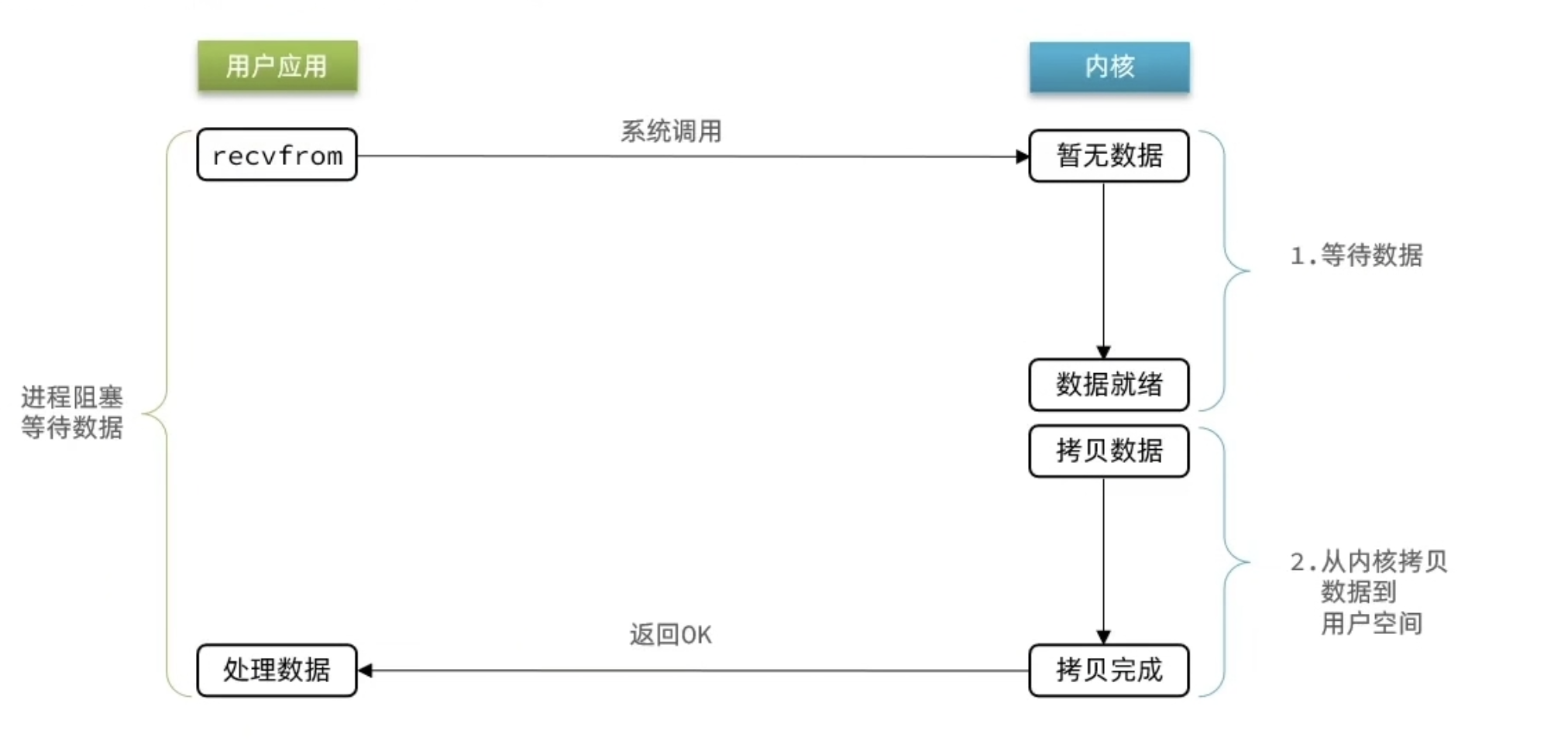
阻塞 IO
磁盘或其他硬件的数据读取到内核的缓存区中 和 从内核拷贝数据到用户空间这两个阶段,用户进程处于阻塞状态
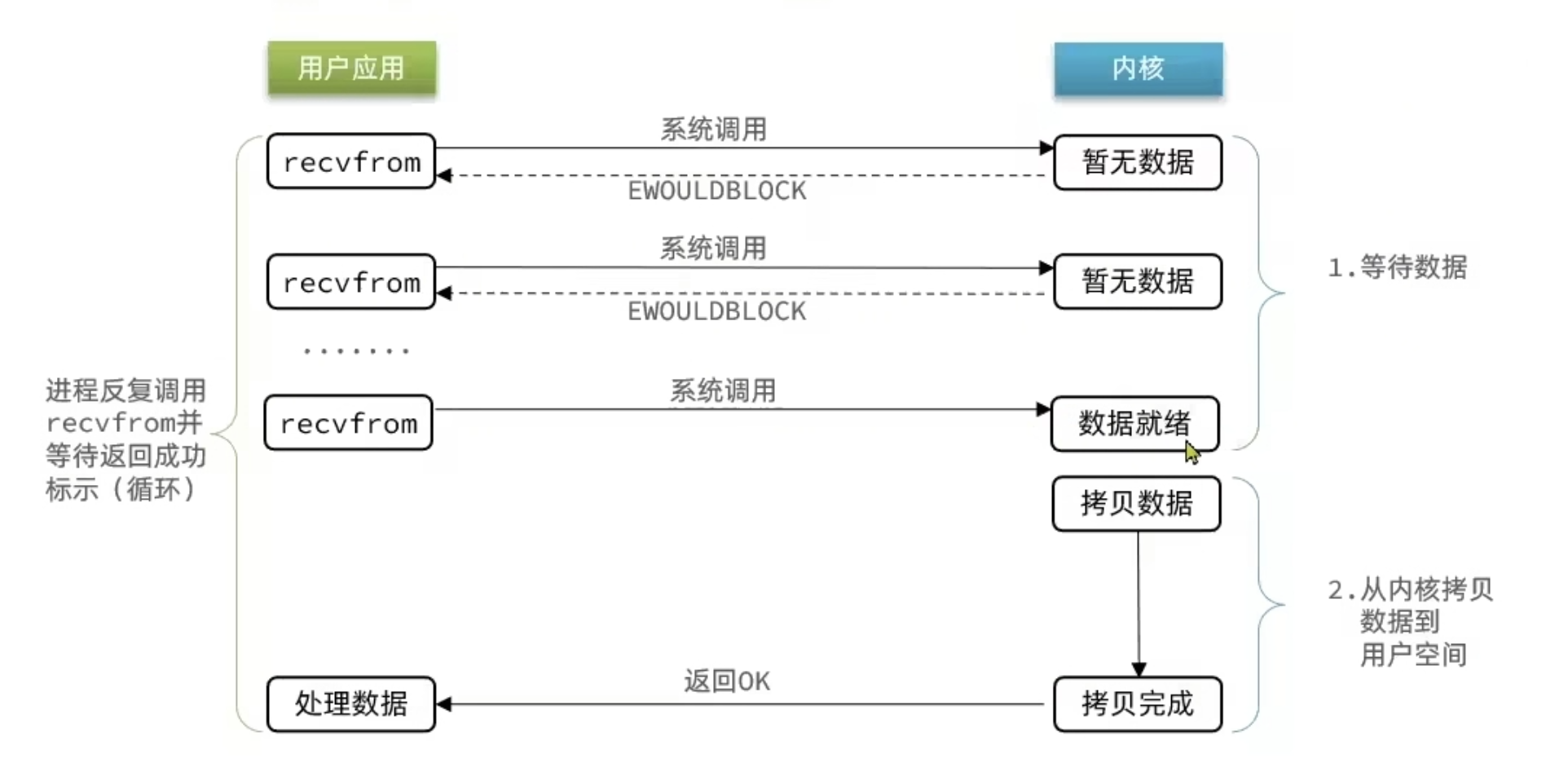
非阻塞 IO
只是把等待获取数据阶段改成了轮询,反复调用recvfrom。这样的忙等待机制,会导致 CPU 空转,暴增使用率。
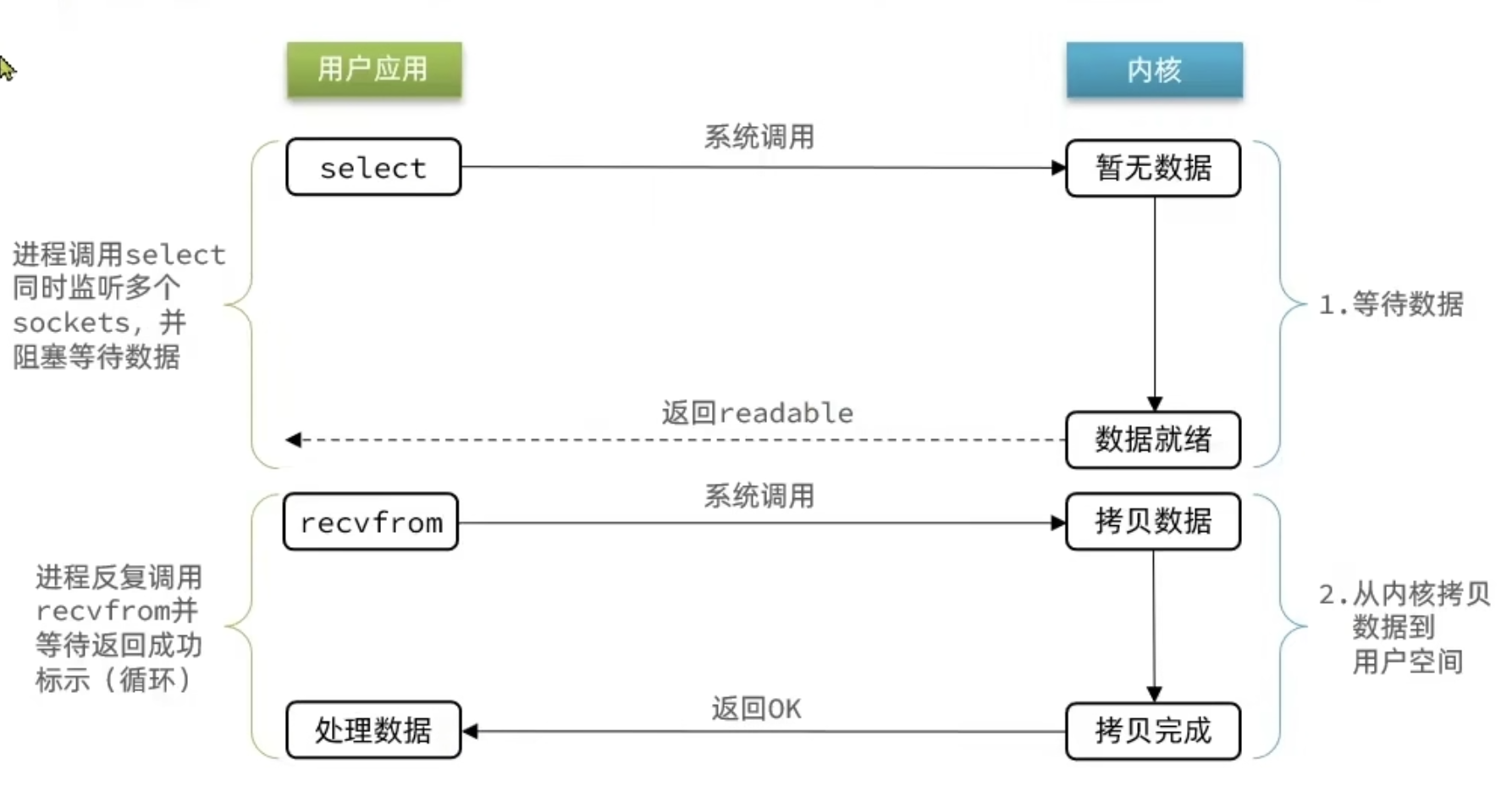
IO 多路复用(重点)
无论是阻塞 IO 还是非阻塞 IO,用户应用在一阶段都需要调用recvfrom来获取数据,差别在于无数据时的处理方案:
- 如果调用
recvfrom时,恰好没有数据,阻塞 IO 会使进程阻塞,非阻塞 IO 使 CPU 空转,都不能充分发挥 CPU 的作用。 - 如果调用
recvfrom时,恰好有数据,则用户进程可以直接进入第二阶段,读取并处理数据
比如服务端处理客户端 Socket 请求时,在单线程情况下,只能依次处理每一个 socket,如果正在处理的 socket 恰好未就绪(数据不可读或不可写),线程就会被阻塞,所有其它客户端 socket 都必须等待,性能自然会很差。
文件描述符(FileDescriptor):简称FD,是一个从0开始递增的无符号整数,用来关联Linux中的一个文件。在Linux中,一切皆文件,例如常规文件、视频、硬件设备等,当然也包括网络套接字(Socket)。
IO多路复用:是利用单个线程来同时监听多个FD,并在某个FD可读、可写时得到通知,从而避免无效的等待,充分利用CPU资源。
不过监听FD的方式、通知的方式又有多种实现,常见的有:
- select
- poll
- epoll
差异:
select和poll只会通知用户进程有FD就绪,但不确定具体是哪个FD,需要用户进程逐个遍历FD来确认
epoll则会在通知用户进程FD就绪的同时,把已就绪的FD写入用户空间
IO 多路复用 - select
select 是 Linux 中最早的 I/O 多路复用实现方案:
核心类型与函数定义
1 | // 定义类型别名 __fd_mask, 本质是 long int |
select 工作流程
用户空间操作:
1.1 创建
fd_set rdfs;1.2 假如要监听
fd = 1, 2, 5;1.3 执行
select(5 + 1, rdfs, null, null, 3);2.4 遍历
fd_set,找到就绪的 fd,读取其中数据。内核空间操作:
2.1 遍历
fd_set;2.2 没有就绪,则休眠;
2.3 等待数据就绪被唤醒或超时(如
fd=1数据就绪);(注:
fd_set会从用户空间拷贝到内核空间,select 结束后再拷贝回用户空间)
select 模式存在的问题
- 需要将整个
fd_set从用户空间拷贝到内核空间,select 结束还要再次拷贝回用户空间; - select 无法得知具体是哪个 fd 就绪,需要遍历整个
fd_set; fd_set监听的 fd 数量不能超过 1024。
IO 多路复用 - poll
对 select 进行了简单改进,性能提升不明显
流程
- 创建
pollfd数组,向其中添加关注的 fd 信息,数组大小自定义 - 调用
poll函数,将pollfd数组拷贝到内核空间,转链表存储,无上限 - 内核遍历 fd,判断是否就绪
- 数据就绪或超时后,拷贝
pollfd数组到用户空间,返回就绪 fd 数量n - 用户进程判断
n是否大于 0 - 大于 0 则遍历
pollfd数组,找到就绪的 fd
核心定义
pollfd 中的事件类型
1 |
pollfd 结构
1 | struct pollfd { |
poll 函数
1 | int poll( |
与 select 对比
- select 模式中的
fd_set大小固定为 1024,而pollfd在内核中采用链表,理论上无上限 - 监听 FD 越多,每次遍历消耗时间也越久,性能反而会下降
IO 多路复用-epoll
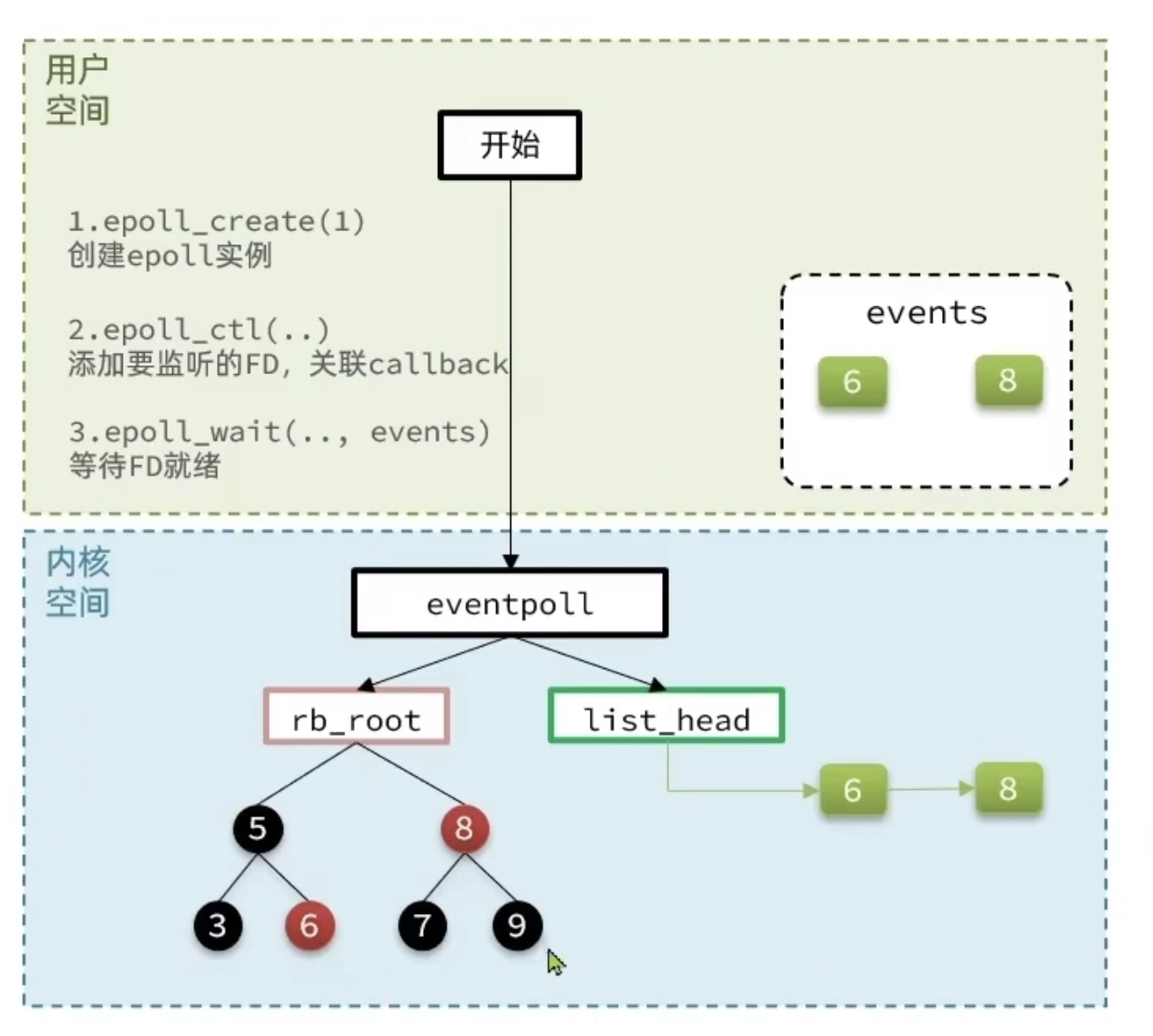
epoll 模式是对 select 和 poll 的改进,它提供了三个函数:
核心结构与函数定义
1 | struct eventpoll { |
epoll 工作流程
- 用户空间:
epoll_create(1)创建 epoll 实例;epoll_ctl(...)添加要监听的 FD,关联 callback;epoll_wait(..., events)等待 FD 就绪。
- 内核空间:
eventpoll结构体维护红黑树(存监听的 FD)和就绪链表(存就绪的 FD);- 当 FD 就绪时,callback 触发,将 FD 加入就绪链表;
epoll_wait直接从就绪链表获取数据,返回给用户空间的events数组。
epoll 怎么解决之前的问题的
基于epoll实例中的红黑树保存要监听的FD,理论上无上限,而且增删改查效率都非常高,性能不会随监听的FD数量增多而下降
每个FD只需要执行一次epol_ctl添加到红黑树,以后每次epol_wait无需传递任何参数,无需重复拷贝FD到内核空间
内核会将就绪的FD直接拷贝到用户空间的指定位置,用户进程无需遍历所有FD就能知道就绪的FD是谁。这类基于实现注册事件分发器的开发模式也叫 Reactor 模型。
事件通知机制
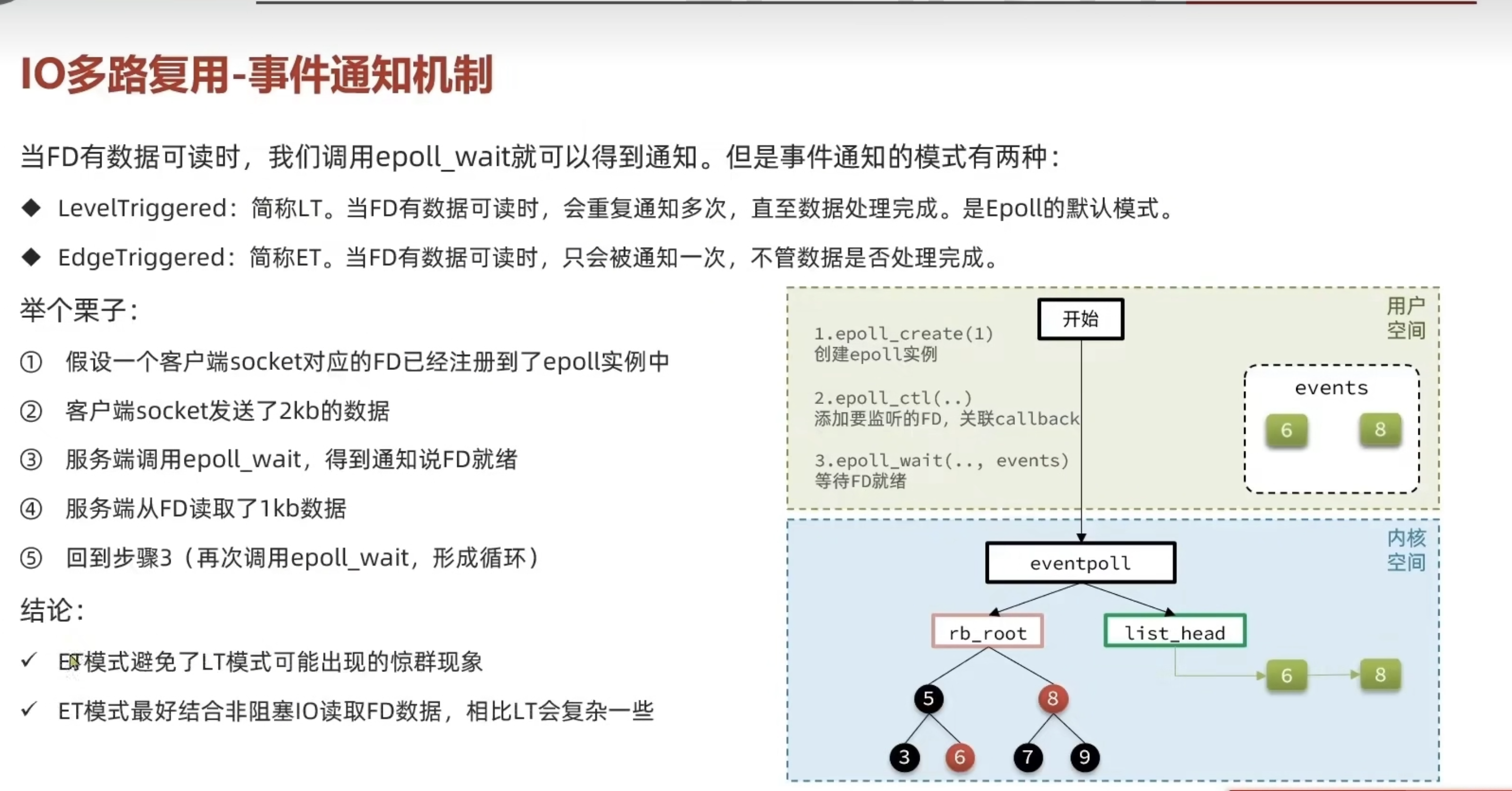
当 FD 有数据可读时,调用epoll_wait可以得到通知,但事件通知的模式有两种:
- Level Triggered(LT,水平触发):当 FD 有数据可读时,会重复通知多次,直至数据处理完成。是 Epoll 的默认模式。
- Edge Triggered(ET,边缘触发):当 FD 有数据可读时,只会被通知一次,不管数据是否处理完成。
举个栗子:
- 假设一个客户端 socket 对应的 FD 已经注册到了 epoll 实例中
- 客户端 socket 发送了 2kb 的数据
- 服务端调用
epoll_wait,得到通知说 FD 就绪 - 服务端从 FD 读取了 1kb 数据
- 回到步骤 3(再次调用
epoll_wait,形成循环)
结论:
- ✔️ ET 模式避免了 LT 模式可能出现的惊群现象
- ✔️ ET 模式最好结合非阻塞 IO 读取 FD 数据,相比 LT 会复杂一些
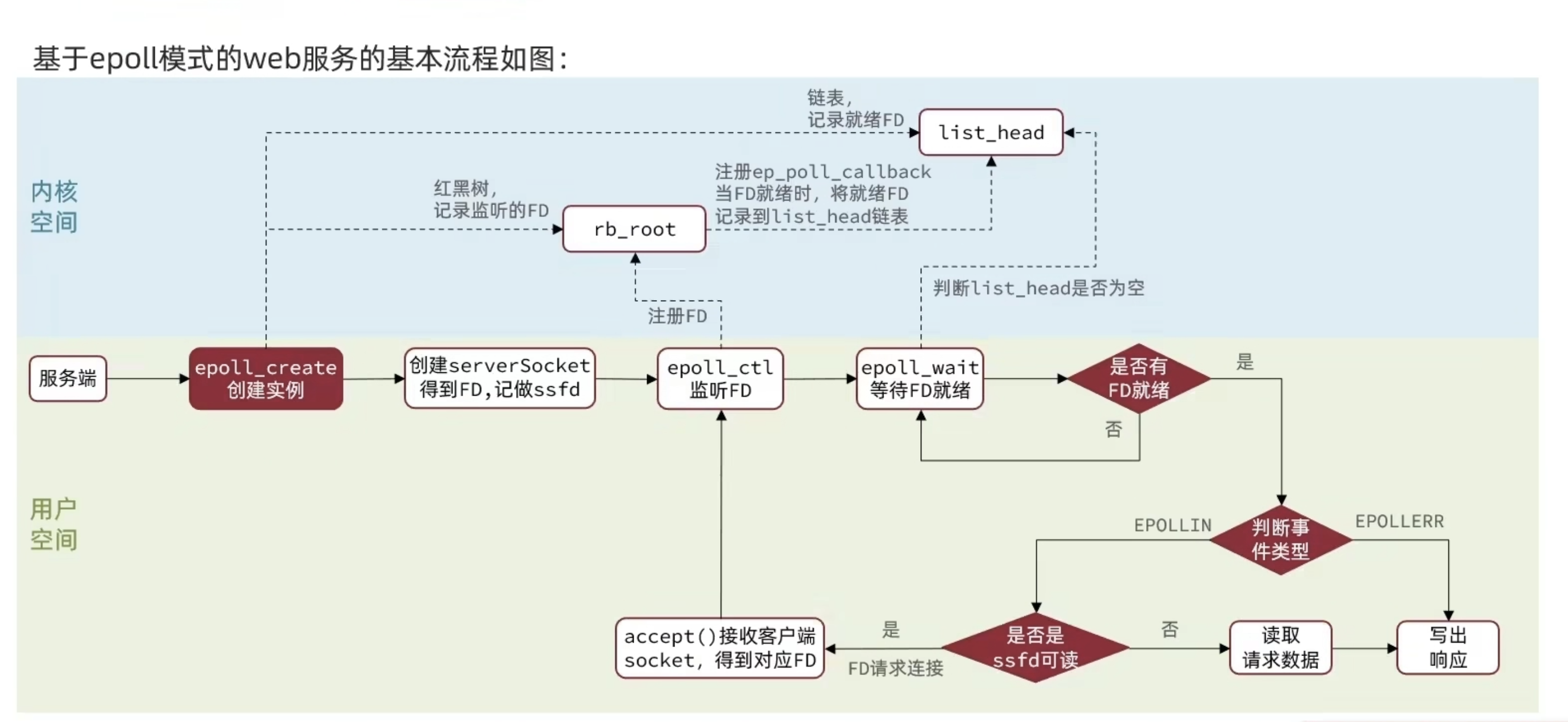
web 服务流程
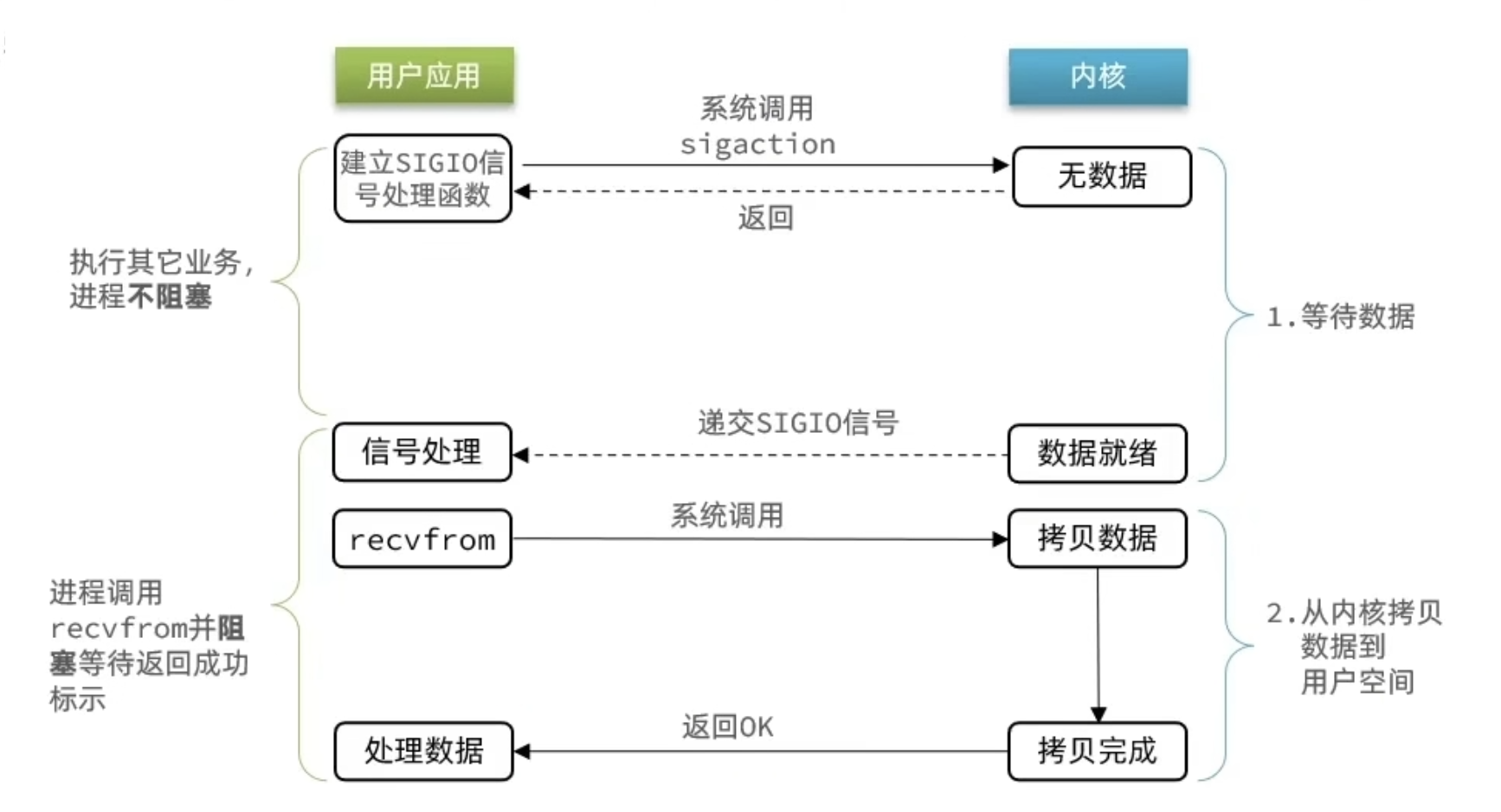
信号驱动 IO
信号驱动 IO 是与内核建立 SIGIO 的信号关联并设置回调,当内核有 FD 就绪时,会发出 SIGIO 信号通知用户,期间用户应用可以执行其它业务,无需阻塞等待。
存在的问题
当有大量 IO 操作时,信号较多,SIGIO 处理函数不能及时处理可能导致信号队列溢出;而且内核空间与用户空间的频繁信号交互性能也较低。
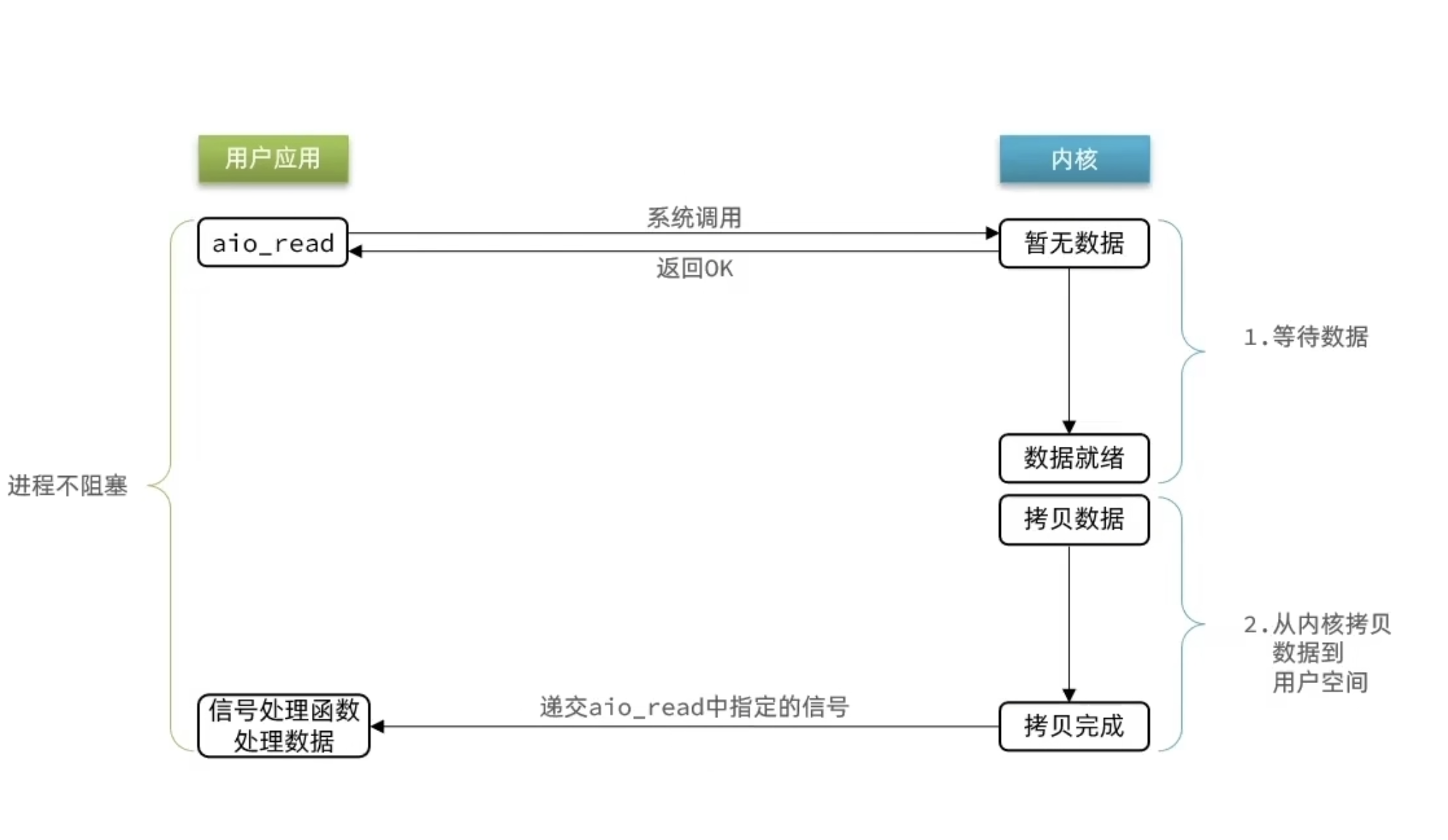
异步 IO
用户只负责发起,接下来全交给内核。高并发下可能导致系统崩溃
IO 操作是异步还是同步,关键在于数据在内核空间与用户空间的拷贝过程(数据读写的 IO 操作),也就是阶段二是同步还是异步的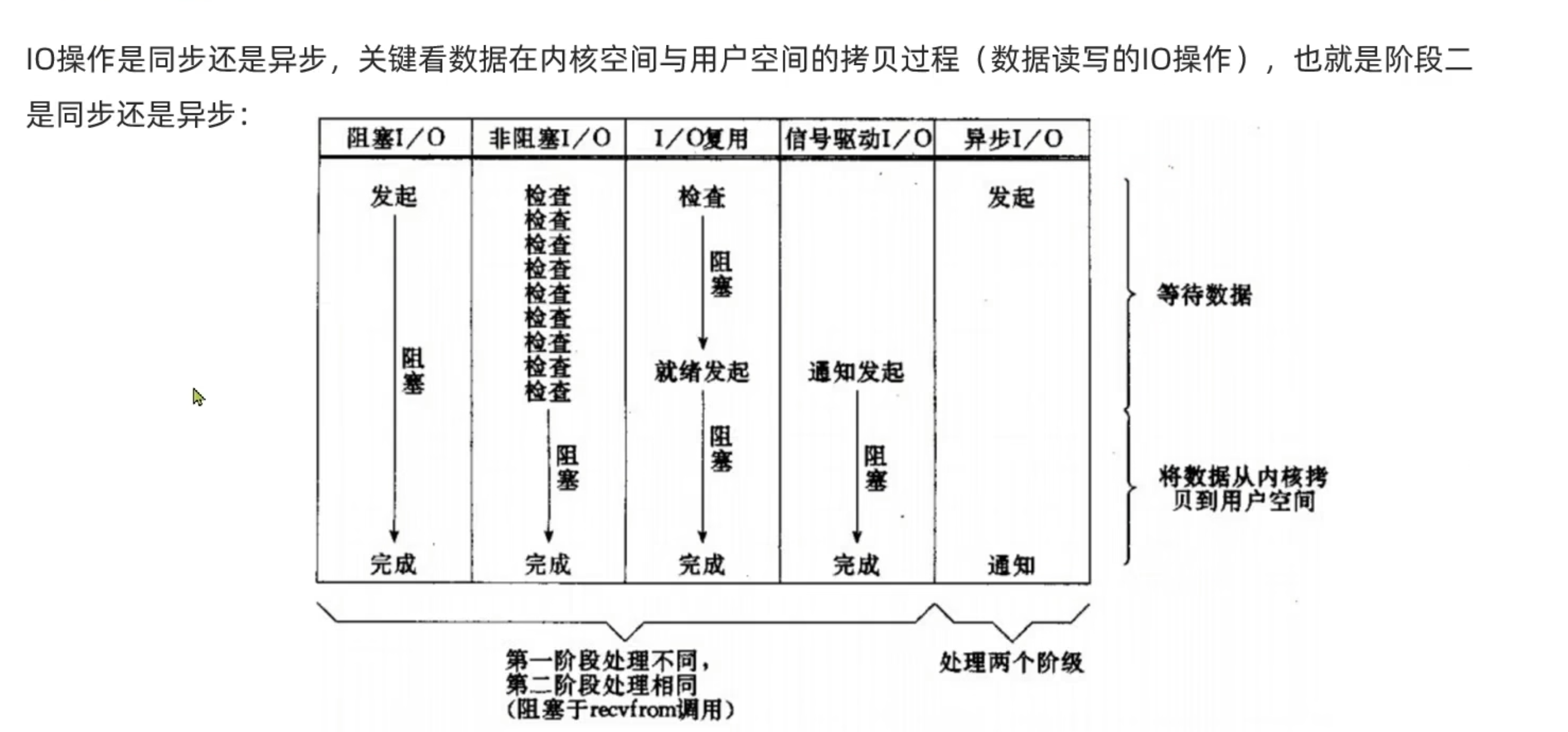
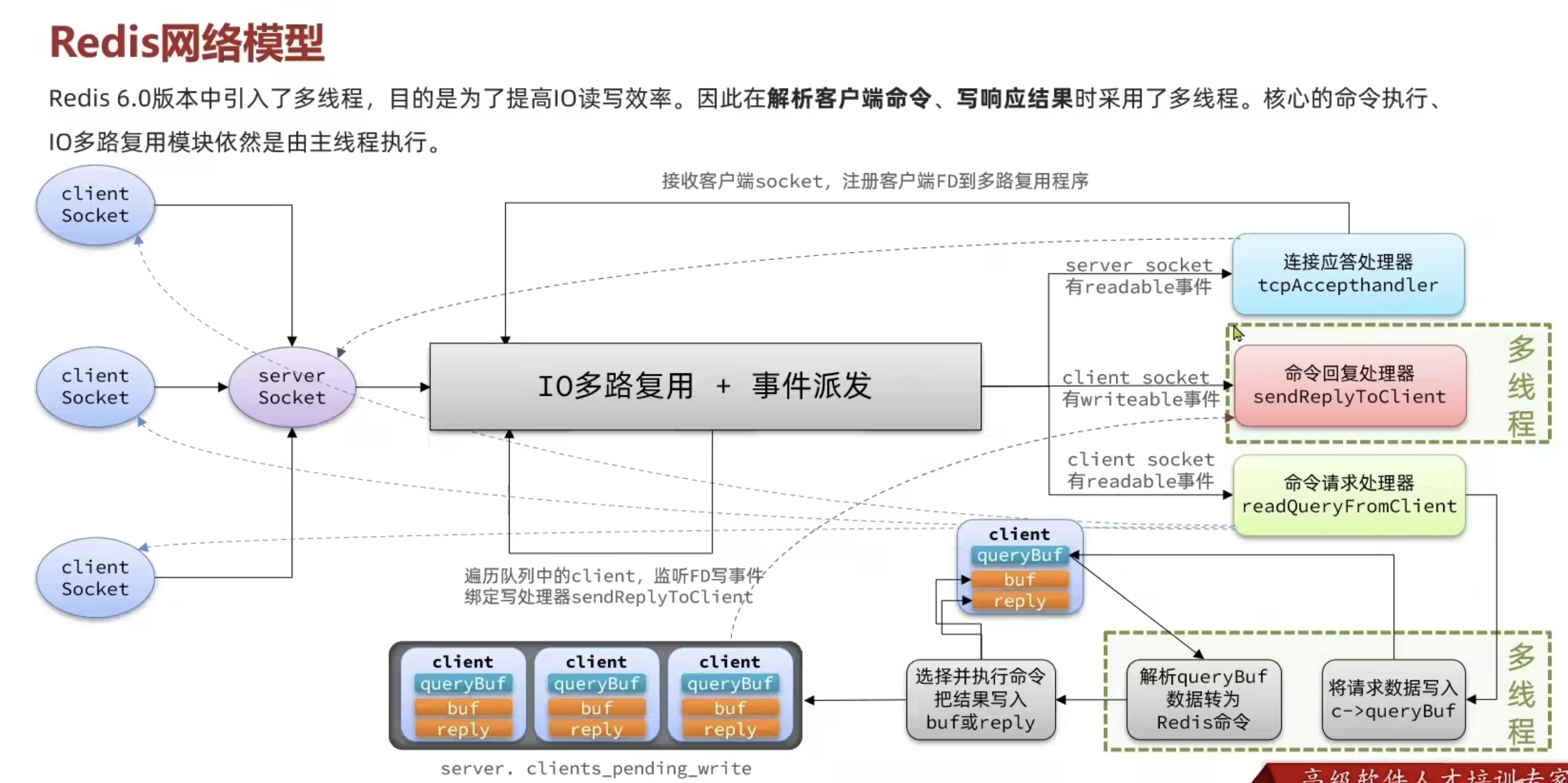
Redis 网络模型
Redis到底是单线程还是多线程?
- 如果仅仅聊Redis的核心业务部分(命令处理),答案是单线程
- 如果是聊整个Redis,那么答案就是多线程
在Redis版本迭代过程中,在两个重要的时间节点上引入了多线程的支持:
- Redis V4.0:引入多线程异步处理一些耗时较长的任务,例如异步删除命令unlink
- Redis v6.0:在核心网络模型中引入 多线程,进一步提高对于多核CPU的利用率
1. 为什么Redis要选择单线程?
- 抛开持久化不谈,Redis是纯内存操作,执行速度非常快,它的性能瓶颈是网络延迟而不是执行速度,因此多线程并不会带来巨大的性能提升。
- 多线程会导致过多的上下文切换,带来不必要的开销
- 引入多线程会面临线程安全问题,必然要引入线程锁这样的安全手段,实现复杂度增高,而且性能也会大打折扣
Redis 通过 IO 多路复用来提高网络性能,同时支持多种多路复用实现,并将这些实现封装为统一的高性能事件库 API(AE):
AE 事件库的核心结构
AE 库通过条件编译适配不同的多路复用方案(如 epoll、kqueue、select),对应的实现文件包括:ae_epoll.c、ae_evport.c、ae_kqueue.c、ae_select.c。
AE 库的统一 API(以ae.c中的条件编译为例)
1 | /* ae.c */ |
AE 库的核心函数(统一接口)
aeApiCreate(aeEventLoop *):创建多路复用程序(如epoll_create)aeApiResize(aeEventLoop *, int):调整事件容量aeApiFree(aeEventLoop *):释放资源aeApiAddEvent(aeEventLoop *, int, int):注册 FD(如epoll_ctl)aeApiDelEvent(aeEventLoop *, int, int):删除 FDaeApiPoll(aeEventLoop *, timeval *):等待 FD 就绪(如epoll_wait、select、poll)aeApiName(void):返回当前使用的多路复用方案名称
Redis IO多路复用流程
其中 aeEventLoop + before sleep + aeApiPoll 就是 IO 多路复用 + 事件派发

Redis 的单线程会循环执行 “监听事件 → 处理就绪事件”,流程如下:
注册事件:
客户端和 Redis 建立连接后,Redis 会把这个连接对应的文件描述符(FD) 注册到 AE 事件库中,同时告诉 AE:“我要监听这个 FD 的读事件(客户端发请求) 或写事件(给客户端回响应)”。
等待事件就绪:
Redis 调用 AE 库的
aeApiPoll(底层是epoll_wait/select),阻塞等待 “有 FD 就绪”(比如客户端发来了请求,对应的 FD 变成 “可读”)。处理就绪事件:
一旦有 FD 就绪,
aeApiPoll会返回 “哪些 FD 就绪了”,Redis 就依次处理这些 FD 对应的事件:- 如果是 “读事件”:读取客户端的请求命令,执行命令(比如
set key value); - 如果是 “写事件”:把命令执行结果写回给客户端。
- 如果是 “读事件”:读取客户端的请求命令,执行命令(比如
循环监听:
处理完一批就绪事件后,Redis 又回到 “等待事件就绪” 的步骤,继续循环。
Redis 通信协议
在 RESP 中,通过首字节的字符来区分不同数据类型,常用的有 5 种:
单行字符串:
首字节是
'+',后面跟单行字符串,以 CRLF("\r\n")结尾。例如返回 “OK”:
"+OK\r\n"错误(Errors):
首字节是
'-',格式与单行字符串一致,字符串内容为异常信息。例如:
"-Error message\r\n"数值:
首字节是
':',后面跟数字格式的字符串,以 CRLF 结尾。例如:
":10\r\n"多行字符串:
首字节是
'$',表示二进制安全的字符串,最大支持 512MB:大小为 0 时代表空字符串:
"$0\r\n\r\n"大小为 - 1 时代表不存在:
1
"$-1\r\n"
示例:
1
"$5\r\nhello\r\n"
$5表示字符串占 5 字节,后面是真正的字符串数据)
数组:
首字节是
'*',后面跟数组元素个数,再依次跟上元素(元素数据类型不限):示例 1(对应
set name 玺朽命令):1
2
3
4*3\r\n
$3\r\nset\r\n
$4\r\nname\r\n
$6\r\n玺朽\r\n示例 2(嵌套数组):
1
2
3
4*3\r\n
:10\r\n
$5\r\nhello\r\n
*2\r\n$3\r\nage\r\n:10\r\n
Redis 内存回收
Redis 之所以性能强,最主要的原因就是基于内存存储。然而单节点的 Redis 其内存大小不宜过大,会影响持久化或主从同步性能。
我们可以通过修改配置文件来设置 Redis 的最大内存:
1 | # 格式: |
当内存使用达到上限时,就无法存储更多数据了。
过期策略
在学习 Redis 缓存的时候我们说过,可以通过expire命令给 Redis 的 key 设置 TTL(存活时间):
1 | 127.0.0.1:6379> set name jack |
可以发现,当 key 的 TTL 到期以后,再次访问 name 返回的是 nil,说明这个 key 已经不存在了,对应的内存也得到释放,从而起到内存回收的目的。
Redis 是典型的 key-value 内存数据库,所有 key、value 都存储在 Dict 结构中。在其redisDb结构体中,包含两个核心 Dict:一个用于记录 key-value,另一个用于记录 key-TTL。
1 | typedef struct redisDb { |
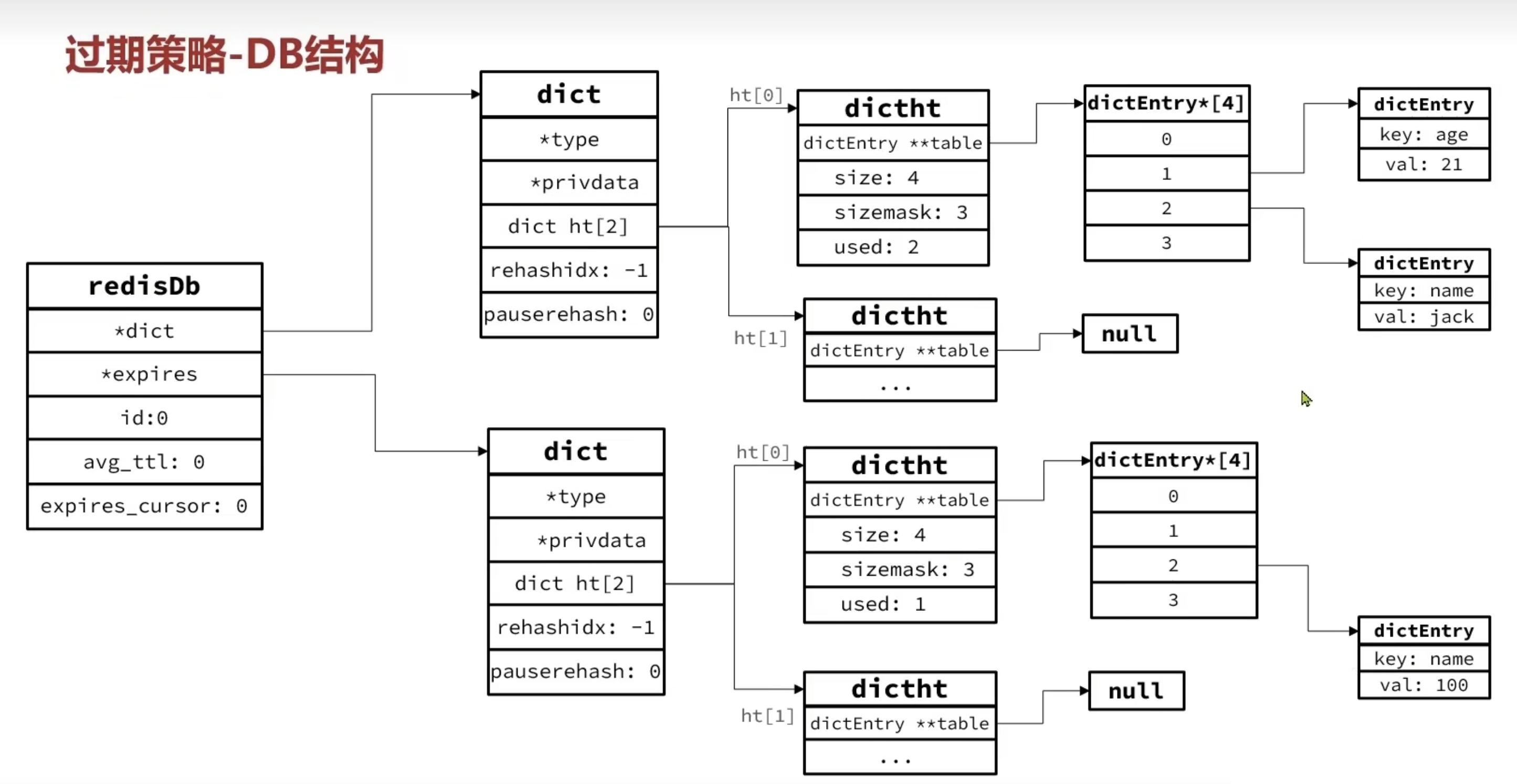
这里有两个问题需要我们思考:
① Redis是如何知道一个key是否过期呢?
- 利用两个Dict分别记录key-value对及key-ttl对
② 是不是TTL到期就立即删除了呢?
- 惰性删除:访问的时候检查 key是否到期,过期则删除
- 周期删除:周期性的抽样部分过期的 Key,然后执行删除
- Redis会设置一个定时任务serverCron(),按照server.hz的频率来执行过期key清理,模式为SLOW
- Redis的每个事件循环前会调用beforeSleep()函数,执行过期key清理,模式为FAST
周期删除
SLOW 模式规则:
- 执行频率受
server.hz影响,默认为 10(每秒执行 10 次,每个周期 100ms)。 - 执行清理耗时不超过一次周期的 25%(即≤25ms)。
- 逐个遍历 db、db 中的 bucket,抽取 20 个 key 判断是否过期。
- 若未达时间上限(25ms)且过期 key 比例 > 10%,则再次抽样;否则结束。
FAST 模式规则(过期 key 比例 < 10% 不执行):
- 执行频率受
beforeSleep()调用频率影响,但两次 FAST 模式间隔不低于 2ms。 - 执行清理耗时不超过 1ms。
- 逐个遍历 db、db 中的 bucket,抽取 20 个 key 判断是否过期。
- 若未达时间上限(1ms)且过期 key 比例 > 10%,则再次抽样;否则结束。
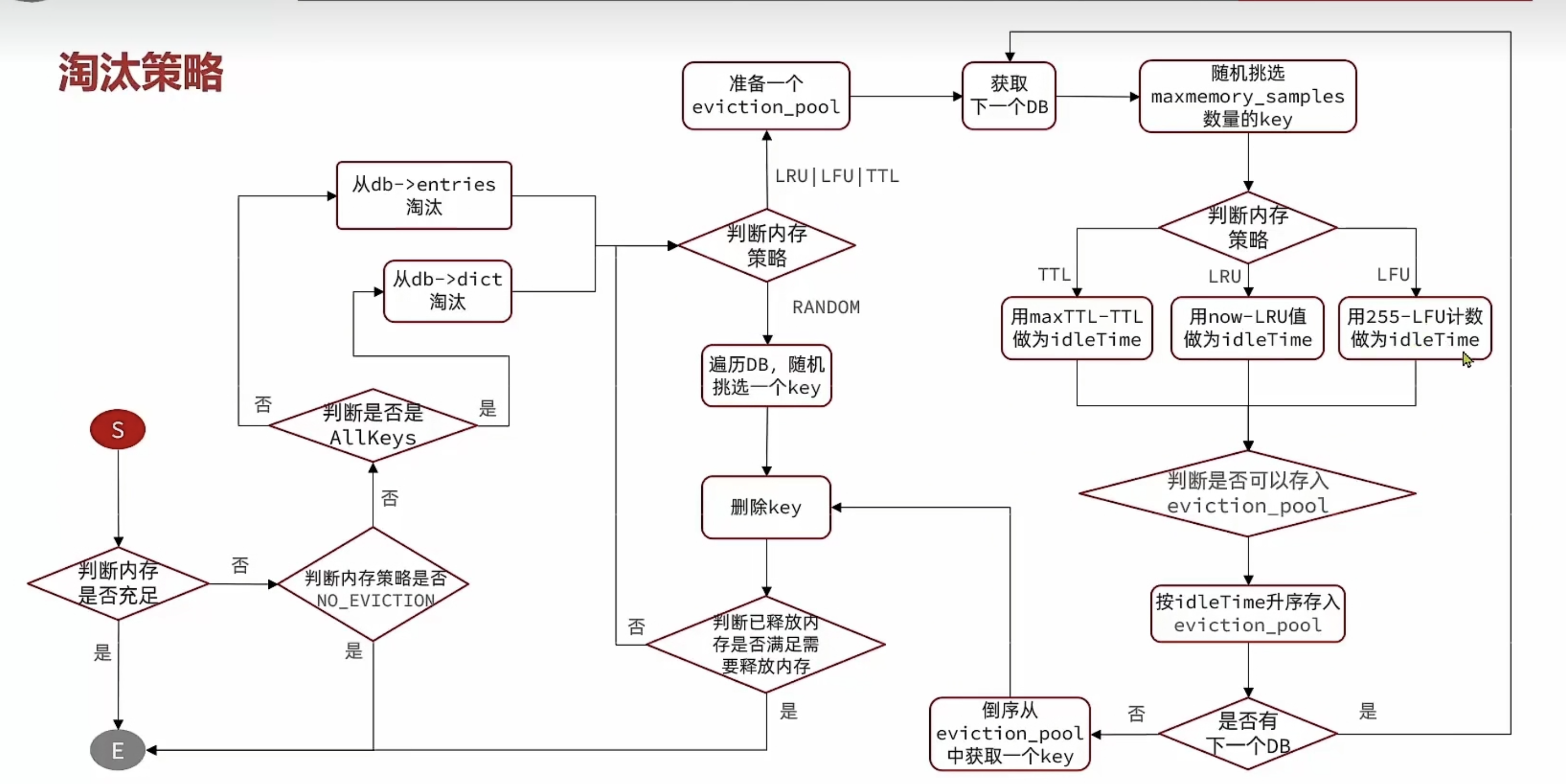
内存淘汰策略
内存淘汰:就是当Redis内存使用达到设置的阈值时,Redis主动挑选部分key删除以释放更多内存的流程。
Redis会在处理客户端命令的方法processCommand()中尝试做内存淘汰
Redis 支持 8 种不同的 key 淘汰策略:
- noeviction:不淘汰任何 key,内存满时禁止写入新数据(默认策略)。
- volatile-ttl:仅对设置了 TTL 的 key,按剩余 TTL 值从小到大淘汰。
- allkeys-random:对所有 key,随机淘汰(从
db->dict中随机选)。 - volatile-random:仅对设置了 TTL 的 key,随机淘汰(从
db->expires中随机选)。 - allkeys-lru:对所有 key,基于 LRU(最少最近使用)算法淘汰。
- volatile-lru:仅对设置了 TTL 的 key,基于 LRU 算法淘汰。
- allkeys-lfu:对所有 key,基于 LFU(最少频率使用)算法淘汰。
- volatile-lfu:仅对设置了 TTL 的 key,基于 LFU 算法淘汰。
易混淆概念:
- LRU(Least Recently Used):最少最近使用。用 “当前时间 - 最后一次访问时间” 的差值衡量,差值越大(越久没被访问),淘汰优先级越高。
- LFU(Least Frequently Used):最少频率使用。统计 key 的访问频率,频率越低,淘汰优先级越高。
Redis 的所有数据都会被封装为RedisObject(简称robj)结构,定义如下:
1 | typedef struct redisObject { |
配置示例(默认):
1 | maxmemory-policy noeviction |
LFU的访问次数之所以叫做逻辑访问次数,是因为并不是每次key被访问都计数,而是通过运算:
① 生成0~1之间的随机数R
② 计算 1/(日次数 *Ifu_log_factor + 1),记录为P,Ifu_ log_factor默认为10
③ 如果R<P,则计数器+1,且最大不超过255
④ 访问次数会随时间衰减,距离上一次访问时间每隔 Ifu_decay_time 分钟(默认1),计数器-1